Assessing Inform (London 2018 talk)
This is the talk and slides from the June 2018 London IF meetup, held at Elephant Studios in London South Bank University on 9 June 2018. I was invited to speak about Inform, past, present and future. I’d like to thank the audience, who were not all from London nor even from England, for their insightful questions. This talk assumes a little familiarity with what is sometimes called parser IF, because it was preceded by an introduction from Emily Short, who led a live play-through of part of Mike Spivey’s recent work A Beauty Cold and Austere, and showed a gallery of contemporary pieces written in this genre. — Graham Nelson
Some of the details about future plans have moved on: see the June 2019 Narrascope talk for an update.

Firstly, of course, thank you for coming out on a Saturday night. I’m really going to give two short talks, one after the other. In the first half, I want to give my own assessment of the Inform programming language, and you must allow for the fact that I am Inform’s creator, and not an unbiased commentator. In the second half, I will turn to what’s wrong with Inform as it stands, and what the plan is for its further development, and in general what I’ve been working on for the last three years, off and on. In that part of the evening, you’ll have to allow for the fact that I am Inform’s maintainer, and therefore in a permanent state of guilt and anxiety about it.

Inform is a domain-specific language, and its domain is the creation of interactive fiction. When it began in 1993, Inform was simply a new hacker tool for making what we used to call adventure games: that is, textual games with a turn cycle in which the player typed commands and the game then revealed an appropriate piece of story — a story partly generated dynamically, but partly following a narrative already laid out by the author. This is a genre of writing which began with recreational computing in the 1970s, then passed through a commercial phase in the 1980s. Inform is called Inform in part because of the classic works of a company called Infocom:

The best of their roughly 35 interactive fictions, a term that Infocom coined, remain enjoyable today. They are pleasing as a piece of Americana — like the movie Back to the Future, the Space Shuttle or the first Apple Mac, Infocom is a slice of the America of the Reagan administration — but they are also, on a good day, successful both as games and as art.

The rise of graphics hardware and a downward slide in the average age of games players made the text adventure commercially extinct by 1990, but this was both an end and a beginning. The countervailing factor was the rise of networking: University student access, home dial-up, bulletin boards, Usenet, magazine cover discs, the web, home broadband, and so on. At the earliest possible opportunity, hobbyists, for want of a better word, took up the practice of writing and sharing interactive fiction of their own. By 1993, a home PC could just about compile a work of IF of the size and complexity of the works which Infocom had needed a mainframe for in 1983. All that was needed was a compiler.
The 1990s were a propitious time for this sort of hobby computing. There were really two computing bubbles in this era. The one people talk about was the dot-com boom, when the potential of websites hit the venture capital market, and startups like Amazon got going. The other was an almost ideologically opposite sort of economy, with the rise of Linux, Perl and Apache, a market in which your wealth, in the form of public standing, was proportional to how much you had given to the community, in the form of code. Jeff Bezos got to be a billionaire out of the 90s, but thanks to my software, I got to marry Emily Short, so you could say we both got to be the world’s richest man.
Not much about the original Inform language was original. It was a C-like language with classes whose compiler could have been a summer project for a graduate student, which is what I was in 1993. Still, it was shaped by the experiences of real users, and iterated rapidly through versions 1 to 5, stabilising as Inform 6 in 1996. When, in 2003, I returned to the problem of making IF, I threw away the entire Inform language and began again, but called the result Inform 7, the next available major version number. I slightly regret that now, in the same way that Apple came to regret calling Mac OS X simply version 10 of their famous operating system, when in fact it was a whole different thing. But it was probably a good decision at the time. ‘Inform’ was my brand, and making it ‘Inform 7’ was a way of declaring that Inform 6 was officially over. (This didn’t work for Larry Wall when he tried to replace Perl 5 with Perl 6, but that was because Larry hadn’t actually written Perl 6 at the time.) At any rate, Inform 7 had its first public release in 2006. It was heavily shaped not only by me, but also by Andrew Plotkin, a long-time member of the Boston IF scene, whom some of you may know, and by Emily Short, our host tonight.
So, then, Inform is available for Linux, Mac OS X, Windows and Android. Apple’s rules exclude it from iOS, but it has otherwise been on more or less every platform. The Mac App Store version gets about 2000 downloads a month, to give some idea of scale. If we look at the TIOBE index, a measure of usage and influence among programming languages, Inform’s best result was 49th, in 2015: just above Mathematica, and just behind FORTRAN. (For comparison, the 49th most spoken natural language is Romanian.)
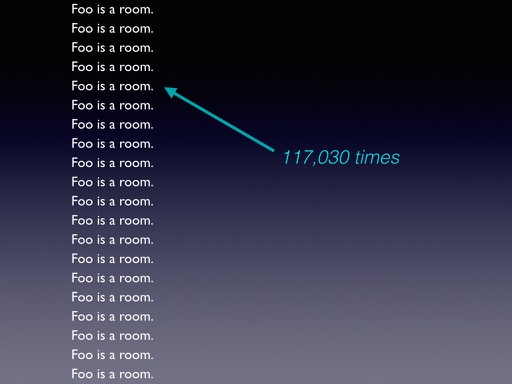
Being in front of a large number of users means that your software has a large number of bugs, in the sense that a bug is a defect you actually know about. The more people participate, the more bug reports you get. My favourite was turned in by the Canadian computer scientist Daniel Fremont, whose research is in finding software defects, and who managed to crash Inform in 2014 by fuzzing it with a program consisting of the sentence ‘Foo is a room.’ repeated 117,030 times. (Other numbers of repetitions didn’t work.)
At certain times of year, fixing that kind of thing is how I spend my evenings and weekends. There’s always a tension between making forward progress on the software or fixing bugs, and to some extent, you have to ask what benefits actual users the most. But a crash is a crash. I did fix Daniel’s bug.

The chief originality of Inform 7 is that it is based entirely on natural language. I want to sketch out some of the motivation for that, and some of the benefits that come from it.
To compare programming languages with natural languages is a little heretical in computer science, but I’m not sure why that is. The development of the theory of programming languages was, after all, spurred on by the early work of Noam Chomsky.

Thus, for example, Donald Knuth took Chomsky’s book on structural linguistics with him on his honeymoon. In spite of this Don is still married to Jill, 45 years later: when you have dinner with the Knuths you talk more about quilting and printing Lutheran bibles than programming, but it all seems of a piece.
I mention Knuth because, of all the Old Masters of computer science, he is the one most interested in the relationship between computer programs and texts. Could we even suggest that a program is a text? It is, after all, a written expression of creativity. Certainly, when running, a computer game can be an artistic experience in the same way that a film, or a play can. But my concern here is not whether the program is art when it runs. I’m talking about whether its source code is a text. We could go down a bit of a rabbit-hole here about playful literary theories. Umberto Eco once reviewed a new Italian banknote as a work of art, describing it as a numbered, limited edition of engravings. But let’s concede that a functional document like a shopping list or a spreadsheet of student names is not a literary text. On the other hand, a recipe by a literary cook like Elizabeth David might be art, even though it also has function. Perhaps the relevant question is: can we experience a program as a text? Can we, in the fullest sense of the word, read it?
A cynical answer might be that if program source codes are texts, why can’t you buy them in a bookshop?

In fact, annotated editions of a handful of programs have indeed been published, most notably TeX and version 6 of the Unix operating system. Two large-scale Inform programs have also been printed in book form. Modern programs can be enormous, of course, and would be unwieldy as a physical book, but even these are often freely readable at repositories such as Github. So I don’t think it could be said that programs aren’t read as texts because they aren’t available.
The problem is rather that source-code spelunking, as it’s sometimes called, is so unrewarding. You pick a file from a mass of files, hoping to get your bearings, but open it to find endless low-level manouevres. There are some suggestive class or function names but it’s hard to get a sense of even the basic plan of how it works.
This problem is made worse, I think, by the aesthetics, or perhaps I should say the ideology, of many working programmers. All programming languages provide for comments, but coders often want to purge this marginalia, disliking any verbose comment as a form of ‘cruft’. It violates, they would say, the ‘Don’t Repeat Yourself’ maxim.

‘Don’t Repeat Yourself’, or DRY, is taught by many make-yourself-a-better-programmer books — a genre of publishing which always reminds me of relationship self-help books. DRY says that the same concept shouldn’t be given more than one expression in the code. But taken to extremes, DRY means that any comment saying what a program is trying to do is redundant, because a program is by definition already a statement of what it does. Don’t repeat yourself, in other words, can be taken to mean: never explain yourself.
I am a contrarian on this. My own programs are written using the doctrine of ‘literate programming’ — an unhelpful name today, implying a bit aggressively that everybody else is illiterate. The name comes because Knuth propounded the idea as a sort of rejoinder, or qualification, to the rise of ‘structured programming’, a practice advocated by the European school of computer science: Edsger Dijkstra, who was Dutch, Niklaus Wirth, who was Swiss, Tony Hoare, who was English. Structured programming calls for programs to be organised into modular parts, rather than being one big soup of instructions. Knuth didn’t disagree, but he seems to have felt that this took away from the sense of a program having a narrative, what we might call a linear plot. In older programs, a human reader could often start at the top, see how it begins, what it does, and how it finishes, following its execution in sequence. By contrast, one reason it’s hard to figure out what’s going on in a big modern program is that it’s more like a landscape than a story. It’s an expanse you can wander about in any direction, never being quite sure what is collectively achieved by the too many components, or in what order. This is not to say that structured programming is a bad thing: I believe it’s essential. But it is not self-explanatory.

Knuth proposed literate programming as a way to explicate programs. He gave an elegant statement of this dogma in 1992, when invited to write an encyclopaedia entry on programming. I like this quote, because it’s so antithetical to what almost everybody in computer science thinks, with a few honourable exceptions (some tools for Haskell, for example, are influenced by literate programming).
Literate programming, then, is a set of tools and practices to mix code with explanatory text. Source code is a blend of code and explanation divided into linked pieces and called a ‘web’. This doesn’t refer to the Internet — it’s actually an earlier usage. There are two fundamental operations on a web: ‘tangling’, which turns it into regular code to be compiled or interpreted; and ‘weaving’, which turns it into a web page, an ebook or a PDF.
How did literate programming influence Inform? Well, one answer is that is that Inform’s equivalent of a standard library is intended to be human-readable. Whereas (say) the C++ STL, or the ANSI C library, are by design opaque to users and presented as APIs, the extensive suite of software supplied with Inform comes as a set of about 500 ‘examples’ — short, readable, copyable and easily lifted from, and presented with commentary.
But the deeper answer is that Inform aims to go further by merging the commentary on a program, written in English, with the program itself: it uses natural language throughout. Inform is of course Turing-complete, but it’s not primarily intended to solve conventional tasks: it’s for the creation of simulations of human situations — which, at some level, is a definition of art.

So let’s now take a look at Inform from a natural language point of view, and start with nouns. Here is a rather minimal Inform program:

Of course the result is not a rich interactive experience, but we’re just getting going.

Now we have a proper noun, Snell Library, and a common noun, student. Proper and common nouns appear in regular programming languages as instances and classes. Languages like C++ or Java aim to police the boundaries of class definitions, and as computer scientists we seem always to want stricter policing, even though we also want to have it both ways with dodges like generics or protocols. Work in linguistics might suggest that we should be less doctrinaire about common nouns and what they describe. In Inform, the concept of ‘kind’ approximates ‘class’, but it was also motivated by the work of the great Polish linguist Anna Wierzbicka. Wierzbicka studies how people make, and then selectively break, categories. A famous example is her definition of the common noun ‘bird’:

Of course an ostrich or a penguin is a bird which doesn’t fly. For Wierzbicka, there’s no contradiction in that: people naturally make semantic categories and yet allow members which violate one of the defining characteristics. You can see something similar in this fragment of Inform:

Note the word ‘usually’. I would suggest that work like Wierzbicka’s might shed some light on long-standing controversies about single versus multiple inheritance in object-oriented languages.
Let’s go back to the simple-looking sentence ‘There are ten students in the Library’, which has quite a lot going on. For one thing, the ‘there’ is a defective form in English, like the ‘it’ in ‘it is raining’, except to emphasise that an existential statement is being made. Inform internally reduces this sentence to predicate calculus, which serves as what linguists call our ‘discourse representation’.

Here I follow an important early-1980s paper of Barwise and Cooper which observes that the basic logical quantifiers ‘there exists’ and ‘for all’ are inadequate for any sensible representation of natural language: Barwise and Cooper added new quantifiers such as ‘there exist 10’, or ‘for most’. Anyway, the proposition says that there are 10 different values of x for which ‘student(x)’, x is a student, and ‘inside(x, Library)’, x is physically located inside the Snell Library.

These basic factual statements, like ‘student(x)’, are predicates. If they involve only one value, like ‘student(x)’ or ‘evasive(x)’, they’re unary predicates; if they involve two, like ‘inside(x, y)’, they’re binary. Skating over some grammatical niceties about common nouns and prepositions, unary predicates are adjectives and binary predicates are verbs.
Given that almost all of the meaning of natural language is conveyed by binary predicates — verbs, that is — it’s striking how much traditional programming languages downplay them. Object-oriented languages, in particular, greatly over-favour unary predicates at the expense of binary. To explain what I mean by this, consider the following piece of Inform:

These few sentences do quite a lot of work. ‘Sophie likes purple’, for example, creates both the person Sophie and the colour purple, whose existence Inform has deduced from the fact that they are connected by the binary predicate ‘liking(x, y)’. In a typical Java or Python program, you would have to simulate this either by putting lots of code about colours into your definition of people, or vice versa, which is a convoluted way of trying to use unary predicates instead: either ‘sophie-likes(x)’ for x = purple, or ‘purple-is-liked-by(x)’ for x = Sophie. Either way round, that’s unnatural, I think. Inform sees binary predicates like ‘liking’ as being first-class concepts in themselves, not as behaviours of either participant.
I think it’s striking, too, that most programming languages have a muddy understanding of adjectives — properties that things either have or don’t have. These tend to be boolean flags attached to objects, making them values as though they are the result of calculations, or else are awkwardly accessed by methods like these:

Which often read ambiguously: does ‘F.atEndOfFile’ change the state, or test it? Are there side-effects? Programmers can often only express these important distinctions by choosing method names carefully — all large companies have a style guide with rules like that — but because this is not a feature of the programming language, compilers don’t police it, and many mistakes are made as a result.
In Inform, on the other hand, one would test or change with syntax such as:

And in general, the syntax to make something happen is the same as the syntax to test it, but using ‘now’ instead of ‘if’. For example:

Note the way that such conditions, by including determiners such as ‘all’, can avoid the need to create and name spurious loop variables. ‘now all of the students are in the Library’ is easier to understand than making a repeat loop, with a necessary but in some sense meaningless variable called S. Anything which reduces the stock of nouns in play makes code easier to understand.
As will have been evident, a guiding design principle for Inform was to imitate the conventions of natural language. But not simply language as we speak it: I also mean the conventions we use when we write and publish it. For example, standard computer programs contain far too many literal numbers and blur together what they’re used for, which causes many errors. Numbers ought to be as rare in programs as they are in speech.
With only a handful of exceptions, natural language uses raw numbers only to count things. We say ‘I am 176cm tall’, not ‘I am 176 tall’. We say ‘My car weighs 1.4 tonnes’, not ‘My car weighs 1.4’. In Inform, you can say something like this:

Moreover Inform uses dimensional analysis to stop you muddling up numbers in ways which wouldn’t mean anything. You can’t add a length to a mass, for example. Nor can you use a mass where you need an number. If you want the mass of the Clio as a number, divide it by 1kg. You can only multiply if you’ve clearly explained what that would mean. For example, write:

and then you’re allowed to multiply them. It was quite a fun bit of physics-nerdery to work these algorithms out. I don’t think I had ever realised that voltage, for example, is not a fundamental unit and that the ‘volt’ is only a sort of verbal shorthand. When your smoke detector runs down, you do not think ‘where have I put my 9 m^2 kg per amp per second cubed batteries’.
Inform also follows natural language conventions as seen in printed texts. You can lay out equations the way they would appear in a textbook, for example; or consider this rather minimal simulation of the Tour de France:

Here we see square brackets used to mean text which isn’t a verbatim quotation, and we have a table of data laid out just as it would be in a book. Tables do not serve every need — Inform also has lists, for example. But I think tables are a form of data structure immediately comprehensible to a human reader, in a way that arrays are not.
Most programming languages have nothing analogous to tenses: everything happens in the present tense. We code about the state of the world as it is right now, and say what happens right now. While it’s understandable that we don’t talk about the future — we can’t meaningfully perform the test ‘if X will be 6’ — it’s more surprising that programming languages do not support ways to refer to the past, because we need to do that constantly. What we do instead is to create variables, giving them names, and write cumbersome code to store data in those variables which we are going to need later on. Then, later on, we inspect the contents of those variables.
Inform suggests that there are partial gains to be made by supporting past tenses in the language. For example, in Inform we can write:

The compiler takes care of all of the supporting code and storage needed — we need nothing other than that line. In effect this line is equivalent to writing separate code, elsewhere in the program, which reads:

At any rate, Inform provides what amounts to a fourth boolean operator to modify conditions, beyond the usual and, or and not: an operator placing the condition in a past tense.
However, I said this was only a partial win. As linguistics people have realised since the pioneering work of the Danish linguist Otto Jespersen, resolving a name — in effect, dereferencing a pointer — has different results at different times. This leads to ambiguity.

The problem here is that ‘the President’ is a variable, reflecting that the Presidency is held by different people at different times. We must evaluate this variable. But when? If we evaluate it in the past, the condition means ‘if the sitting President has ever been ill while in office’, and will be true if Dwight Eisenhower caught cold in 1955. If we evaluate it in the present, the condition means ‘if the current President has at any point in his past been ill’, and will be true if, for example, Donald Trump had measles in 1975.
But this latter interpretation has serious consequences. When we are able to perform the measles test, back in 1975, we have no way of knowing that Trump will be President. That means we have to test everybody, all of the time, just in case they turn out to be President some day. That requires a lot of storage and incurs a heavy run-time speed penalty. Inform therefore reads ‘if the President has been ill’ as the question ‘if it has ever been true that the sitting President is ill’, which is cheap to test and can be stored in a single bit. Nevertheless, that may not be what the author intended; and evaluating variables in the past is problematic if ‘the President’ is not a global variable, because you can’t evaluate it in the past if, like a local variable on the stack, it didn’t exist in the past. These questions are much subtler than they appear, and are the reason why Inform doesn’t go further into the world of tenses than it does.
I want to mention one other aspect of natural language which can be troublesome for programming: punctuation.

Conventional programming languages, such as C, are aggressively punctuated. By this I mean not only that C code is replete with commas, brackets, braces, semicolons, and colons, but that other requirements — such as that identifiers cannot contain whitespace or use reserved words — combine to produce an apparently unambiguous language. And this has many advantages.
But at first sight, natural language seems almost completely the opposite: it is riddled with ambiguities.

My favourite was an actual headline in the local newspaper in my home town, the Oxford Mail: HEATWAVE BONE BREAKS CLOG HOSPITAL, which is what linguists call an a garden path sentence; or there’s the famous antanaclasis ‘Time flies like an arrow; fruit flies like a banana’. If English had a form of punctuation marking which words are verbs, such ambiguities would be impossible.
And because of this, many computer scientists are wary of natural language as a way to express a computer program. In fact, though, the situation is not as clear-cut as saying that a language like C is precise whereas English is a lottery. C is very ambiguous in resolving nouns. There’s nothing to prevent multiple functions being called ‘printf’, and this has to be resolved using scope and namespaces. An identifier for a variable is not syntactically different from an identifier for a function, and this has to be resolved by looking at its meaning. In both cases, ambiguity is resolved using an understanding of the context in which the usage was made. That is exactly how natural languages function, too. So the difference in ambiguity between programming languages and natural language is one of degree, and is not an absolute.
To conclude this first half of my talk: did natural language turn out to be a good way to write a computer program?

The merits are: familiarity; a low barrier to entry, so that novices, even schoolkids, can get at least something to work quickly; conciseness, in that a lot of boring code becomes unnecessary; and perhaps a greater ease of expressiveness, because the lineaments of the language more closely follow our cognitive habits than would be true of, say, C++.
The demerits are: unfamiliarity, in that we’re not used to coding in prose; a high barrier to entry, as a result; verbosity, in that some arithmetical or data-heavy computations probably are better expressed in formulae; and perhaps, greater ease of expressiveness, which though it’s a good thing in some ways can also lead us casually to write inefficient code.
So I freely acknowledge that the benefits are double-edged. But they are real.

Let’s look at the Inform project as it stood in 2015. As has been widely noted, it hasn’t been updated in the last three years, and the reasons for this will become clear in the second half of my talk. If we stood back in 2015 and asked, is Inform successful?, what should we say? Here’s the optimistic view first.

With all due modesty, I think I can claim three successes for Inform.
(1) It reduced the barrier to entry for would-be writers of interactive fiction. So, in a different way, did the wonderful tool Twine: I’m not by any means claiming any unique virtue here. But welcoming in beginners is important. It’s not an accident that Inform and Twine, between them, account for most of the writing being done in this genre.
(2) Inform has been a sort of laboratory: a testing ground to see if natural language is possible as a means of coding. Some features from Inform have made their way into other programming languages. Inform has also been a sketch-pad: it gets used for purposes other than IF, such as procedurally generated text, or prototyping in the games industry. There is no triple-A game written in Inform, but there are several whose mechanics were sketched out with it.
(3) Finally, what I’m proudest of, when I look at Inform, is that it has been used to make a great deal of art. Inform has made somewhere between 1000 and 2000 finished works of art (not counting little examples and demos, or classroom exercises, or homework). That’s a small number in computing, but quite a large number in art. It’s about the same as the total number of plays ever performed at the National Theatre.
Now I’m going to say what I think is seriously wrong with Inform in its current public release. It was very well tested and is widely used, but that is often true of software in need of generational change. As I looked at Inform in 2015, I saw a number of existential crises facing it — by which I mean, issues that threatened to end its life for all but antiquarian purposes.

One thing to remember that I am a self-taught amateur programmer…

…and that I have a day job, actually two day jobs. I can’t devote my whole attention to Inform. But that said, I do continue to work on it, and rumours that it is rusting forgotten in a tool shed are exaggerated.
(That cartoon was xkcd 1513: Code Quality.)
With that disclaimer made, I’m going to get into the internals, just as I knew what I were doing. I talk about Inform being in crisis, I should first say how Inform worked in 2015. The user sees a friendly Mac, Windows or Linux app, but that’s really just a wrapper on top of some lower-level tools. When you click ‘Go’, the source text is translated into a website or story file by a series of programs, each transforming it in turn:
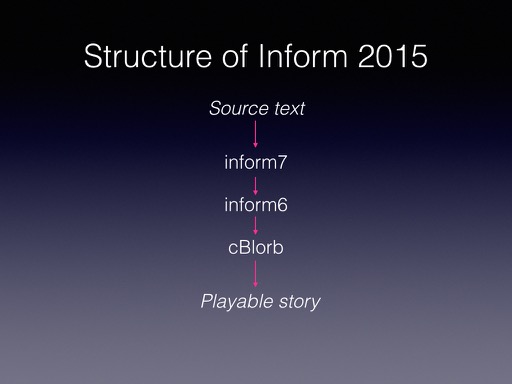
So what was wrong with that? Well, plenty:
(1) ‘inform7’ did far too much for one stage. The code was hard to isolate faults in. It had become the classic oil tanker that takes a long time to turn around. In part that’s because it was and is written in ANSI C, a portable but low-level language making it difficult to abstract high-level concepts. It has been refactored many times — once every year, I ask myself, what is the worst design decision in this program?, and then change it — but too many data structures express only parts of an overarching concept, with that overarching concept somehow not being visible in the code. (‘Adjective’ would be a good example of this.) In short: ‘inform7’ was too big not to fail.
(2) Being written in C is not a threat in itself, but like many old C programs, inform7 was prone to insecure string-handling and erratic Unicode support.
(3) Although the tools in this chain were in one sense independent, they were cranky to use without the Inform UI as life support system. They were also inconsistent in niggling low-level ways — handling long filenames, say, or filenames with strange Unicode in.
(4) The unreleased tools needed to build and test Inform were far worse, some being huge Perl scripts which were just mazes of twisty little passages. They were nowhere close to being releaseable in quality. One reason Inform hasn’t been open source in some years is that this infrastructure was such a mess. But not being open source is an existential threat right there.
(5) Inform makes something that people don’t always want: a work of parser-IF sealed up in its own virtual machine is great for classical IF authors — the ‘playable story’ at the bottom of my diagram. But what if people want a text generation engine they can use in a Unity project, or an iOS app with a completely different interface paradigm?
So, then, a number of calamities.
This last part of my talk is a secret history of the last three years, and what I’ve been working on to address these issues.
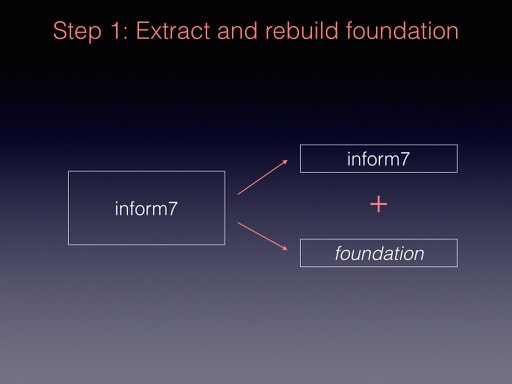
Step 1 was to adapt inweb, the literate programming tool used for Inform, so that it could break projects up into modules. I then began moving the lowest-level code from inform7 into a module called ‘foundation’: memory management, filenames and pathnames, dealing with the command line, string handling, HTML and Javascript, making EPUB books, and so on. In the process, I abolished all use of C-style strings, migrated to wchar_t characters, and removed all fixed-sized arrays.
Step 2. All of the outlying Inform command-line tools were rewritten as inweb projects using this common foundation module. The complete suite is now as shown. inform6 is off to the side because it’s a separately written open-source tool: I haven’t altered it and don’t for the moment intend to.
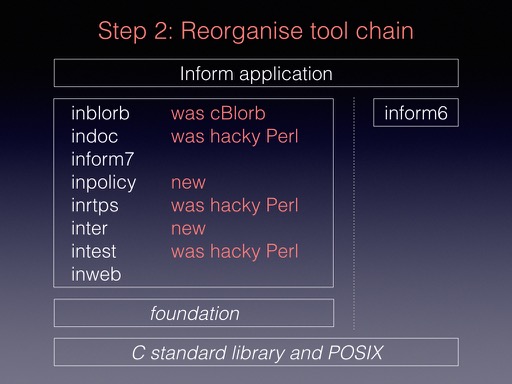
‘intest’, which started as a hacky tool for running test cases through Inform, is worth mentioning as a tool which has been completely rewritten. It’s now quite a capable tool for testing any command-line app with broadly textual output: a mini-language enables the user to set up and automate batches of tests, spread them across processors, collate the results, and so on. I’ve used this to define test cases for all of the tools above.
As this little screenshot from the Terminal shows, the whole Inform infrastructure now works fine at the command-line, and doesn’t need a whole lot of other software already installed before you can use it (Perl, for example).
Step 3 was to further subdivided inform7 into modules, as shown here.
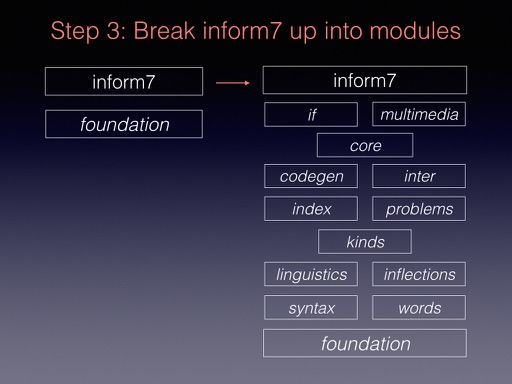
These modules have mutual dependencies, but it’s possible now to compile some of the input end of Inform on its own, which has potential for making hybrid compilers in future. For example, compiling just foundation plus words gives a program which reads in source text, breaks it into words, works out the vocabulary used and stores it all efficiently: you take it from there. Adding the syntax module lets you breaks down into sentences, identifying the verb, and so on. (This is in fact done in order to unit-test portions of the compiler when building Inform.)

Step 4 is probably the most significant thing I’ve done: ‘inter’. The new process for compiling a story with Inform is now one step longer, as this diagram shows. ‘inter’ is intermediate between I7 and I6. For efficiency’s sake, it can be compiled either as part of a larger program (so that it needn’t be launched as a process), or as a stand-alone tool. It takes as its input a new low-level but abstract definition of a story, and outputs Inform 6 code ready to pass along.
This abstract definition, called inter code, can exist either as bytecode in memory, or written out longhand in text, and the ‘inter’ tool can convert in both directions. Inter is quite readable in text form:

When compiling an Inform story in the GUI, all inter code normally exists only as bytecode in memory, for speed, but for example you could instead at the command line do something like this.

Why is this a good idea?
First, I6 code is fiddly to make, and I wanted to move that complexity out of the inform7 tool. Second, though inter currently generates I6 code, in future we might imagine it generating other languages — for example, C-sharp code for import into Unity, or even Javascript. This is a long way off, but at least is architecturally imaginable. Third, inter provides a basis for a form of linker, merging code compiled at different times: code made by inform7, or raw Inform 6 code, or code in the Inform template layer.
The design of ‘inter’ is motivated by that of LLVM, for any compiler enthusiasts here. Like LLVM, ‘inter’ has a pipeline architecture, configurable so that you can perform the transformations you want, in whatever order. This makes experimenting with new features easy: I can imagine people contributing peephole optimisation steps, for example. Two experiments I’ve made already are:
(i) Eliminating unnecessary code — for example, at present every story file contains code for sorting tables, whether or not any tables will ever be sorted. Removing that sort of thing appreciably reduces story file sizes.
(ii) Linking with a precompiled version of the Standard Rules — this is a tricky feature and I’m not sure it will be enabled in the next public release, but it does work on the 2000 or so test cases currently in place, and makes Inform run about twice as fast on them.
So where have I got to, as of today?
Well: there’s much more work to do on inter. What I’ve got does everything described above, but too much I6 generation still happens inside I7 and not inter. For example, a typical rule is generated to inter like this, with a huge wodge of I6 passed essentially verbatim.

This makes use of a necessary, if regrettable, feature of inter, allowing it to be passed raw I6 code in a ‘splat’. There was a similar feature at one time for values, called a ‘glob’: it was a milestone when inform7 no longer produced any globs, and it will be a bigger one when inform7 can do without splats.
Here’s inform7 producing rather better inter code:

As can be seen, inter, like all low-level languages, is verbose. It is designed to be written by other programs, not by people.
This major restructuring of Inform, which has taken three years to carry through, aims to address four of my five existential crises. It’s now making real progress, I think, and my plan is to make a public release later in 2018 which pushes some of this new code out to real users. If all goes well, they won’t notice the difference at all. That’s the life of the software developer.

All of that sounds like worthy software engineering, or I hope so. But how does it help with my fifth crisis: the need to make more flexible forms of interactive fiction, and to break away from command-line interfaces as the only paradigm?
Ultimately, it may actually help quite a lot, because of the (speculative, future) ability to translate inter into code which could be used in Unity projects.
But that is only one aspect. I believe that it’s time to make a decisive step into a rapidly-establishing world in which the object produced by IF is an app (Hadean Lands, 80 Days), or a website (Twine, Undum and so on), rather than a story file. Inform already has a tentative foot in this world, in that it can produce websites with embedded interpreters, and an Inform story file can be souped up with a lot of work into an app. We need to do more. The websites we can make are too limited, and the apps too hard to make. At the same time, we need to embrace a diversity of possible user interfaces: pure command parsing; button or other gadget-enhanced command parsing; choice-based systems with touchable buttons; hypertextual choice interfaces. In doing
all of that, we need to provide the authors of such essentially choice-based IF with the right kind of world modelling. What we have now, certainly, but also more flexibility and ease in setting up plot structures and dialogue. I see all of these things as complementary.
Work on this has really got no further than speculative design documents, but my idea broadly is to unify different UI paradigms by regarding a story as a sequence of choices, in between which text is produced. (In some stories, having taken no action when some real-time timer runs out may itself be a choice.) Each choice results in either (a) an action, or multiple actions; or (b) a scene transition.
Let’s look at what Inform might be like to write, for different UIs.
— Using the command parser UI, the player makes a choice by typing a command, and the result is an action. That’s what we have now, of course.
— Using a touch-based UI, the source text will need to define what options are available at any given time.

The UI would then, in some way, offer touchable buttons for whatever options are available.
— Using a hypertext UI, the author would instead write something like:

At the normal point where a command-parser IF would produce the prompt and wait for the keyboard command, a hypertext IF would simply wait for the player to click one of the links currently exposed on screen.
This is only the barest outline, but the general aim is to provide for simplified and more flexible user interfaces, but retain the full strength of Inform for modelling a background world and generating text. Most of the hard work in web programming terms would be done by Vorple, a powerful set of Inform extensions by Juhana Leinonen, who is here tonight. Vorple already allows for a wide range of effects. And we want to make it possible to produce not only interactive websites but also beautiful ones out of the box, with some of the typographical magic which made Ian Millington’s undum, or Inkle’s Eighty Days, such an experience. Lastly, and in keeping with where Inform came in, we need to make everything almost transparently easy for the aspiring author.
So that is where Inform is. You will see that as this talk has gone on, I’ve slid more and more into the future tense — into things it doesn’t do yet, but which I want it to. That’s as it should be. The goal of software like Inform is to make a little contribution to culture, and culture is always something moving and changing, as artists innovate. Software that isn’t changing and developing leaves the scene because it doesn’t keep up with the creativity of its users. So Inform must change, and must develop. It’s a work in progress.