Opening Inform (Narrascope 2019 talk)
This is a talk and slides from Narrascope 2019, held at MIT, Boston, on 14-16 June 2019. It’s a sequel to a talk given in London a year earlier, when I went into “literate programming” at greater depth, but when the design of Inter was more embryonic. I’d like to thank the Narrascope organisers for fitting me in to their schedule, and the attendees for their questions and for many helpful conversations, besides the whole atmosphere of what was, for me at least, an inspirational gathering. — Graham Nelson

There are people in this room who have been using one version of Inform or another for nearly thirty years. It was and is dedicated to two of the modern pioneers of IF, and this is one of those rare moments when we are together in the same room — Emily Short, whom I later married, and Andrew Plotkin, whom I have not as yet married. This isn’t the moment to give a description of Inform, but briefly, it’s a natural language-based system for describing situations and how to interact with them. Here’s a quick example.

… As you see, this sets up some physical concepts - length, area and weight - and some vocabulary to talk about them: the verb to weigh, the nouns length, area and weight, the adjectives light and heavy, and three scientific notations. For a single screen of code, that’s a lot. But I can skip to the next page really quite quickly, because you don’t need to remember any of it: it’ll all look natural in use.

Now we have a physical situation: a room with a balance platform and a couple of things to put on it. At the end is a short test script for some dialogue:

And there it is. A complex physical world which we can interact with, in just a couple of minutes. There’s a lot more to Inform, but you get the general idea.
In a quiet way, Inform has become quite widely used. According to the TIOBE index, a measure of popular usage of the world’s programming languages, Inform ranks sometimes right at the bottom of the top 50, sometimes somewhere in the second 50. Charts like this are dominated by the big general-purpose languages, C, C++, JavaScript and Python, and the usage curve falls off logarithmically fast. Being 50th means being orders of magnitude below the winners. Still, only a handful of domain-specific languages appear in the top 100 - Mathematica is the other one hovering on the top 50. (Twine would almost certainly also be in this range if it met the slightly narrow definition of programming language used by TIOBE.) Something else Inform and Mathematica have in common is that they are closed-source, whereas most modern languages have open source reference implementations. But Inform won’t be closed for much longer, and that’s my topic today.
I will begin, if I may, with a few reflections on large software projects, and how we think about them, versus how they really are.

The analogy we use is often architecture, and we like to use words like “architect” or “builder”, and “foundation” or “support” or even “scaffold”. In the absolute freedom of our text editors, we can make perfect constructions with elegance, permanence and function. We like the idea that a sketch becomes a blueprint becomes a building, all perfectly planned out.
Of course real software projects aren’t like that, and I think it’s instructive that real buildings aren’t like that either. One that’s going up now is Gaudi’s masterpiece, the Sagrada Familia cathedral. Here are the cranes at work:

In October, the project was granted a building permit by the Barcelona city council; and not a moment too soon, since they broke ground in 1880. Some of the most basic issues about this building are unresolved still. For one thing, how will anyone get in, or even be able to see the Glory Facade? It’s blocked by neighbouring housing. And most visitors may think the cathedral is nearly done, but the central spires, scheduled for 2036, are going to be twice that height. If you visit on a weekday, there’s a constant noise of cutting and you can get a faceful of stone dust. The Sagrada Familia is, in short, simultaneously a cathedral and a building site.
As you look at it, the first thing that hits you is the head-rush of seeing genius at work: proper Renaissance-grade genius, with the arrogance that goes with that. The second thing is that it’s a patchwork of old and new stone, built in fits and starts. That makes it a locus of argument and disagreement. The Passion Facade, seen here below the arch, was a very controversial addition in the 1970s. But even if Gaudi’s original plans had been complete, which they weren’t, they wouldn’t now make much sense. He couldn’t have imagined digital stone-cutting mills, which they now use. More delicately, he had no conception of how much society would change while the building was going up. When he was asked about the slow pace of building, he famously said: “My client is not in a hurry.” But in truth, his client has changed. The Sagrada Familia is headed for a future as a tourist destination, and it needs ticket kiosks and turnstiles and a coach park.
Isn’t this also how a lot of software projects go?

Just on that last point, Gaudi was run over by a tram in the street in 1926 and killed outright, leaving his papers and models in an unclear state. We all of us think we have more time than we actually have.
Where software is not like masonry is that nothing is irrevocable. You can rebuild the foundations while the towers hang in place in midair waiting for you to finish. You can, as it were, move the whole cathedral four feet to the left. But this is a lure. You always have to ask: am I making these changes for any good reason? So I want to explain why I have nevertheless spent the last three and a half years on an extensive rebuilding project. My previous maintenance plan for Inform went like so:

These annual stints of rewriting were somewhere between gardening and jungle clearance. Much of it was trying to make linguistic concepts mesh better with Inform’s data structures, especially in the early days. One summer I spent a week sitting at a table on the terrace of a villa near Menton, looking out at the Mediterranean —

In point of fact it was an awful shack, with vipers living in the grass, and it was a two-hour climb down to the sea, and a four-hour climb back again. Still, for one solid week, I unified the two different data structures for kinds of value and kinds of object. This was a frighteningly large refactor, but it ultimately removed many edge cases from the language.

Eventually, though, every old building reaches a point where routine maintenance is not enough. The only option is temporary closure, and scaffolding, and promises of a grand reopening.
Inform reached that point in 2015. It wasn’t closed in the sense of not being taken out of use, but it stopped offering new features. It will reopen later this year. I am open-sourcing it after rather than before this renovation because the work was so very disruptive, making major structural changes and touching almost all of the 250,000 lines of code. For long periods, sometimes over a month at a time, it couldn’t even build.
But not any more, and it’s time to take a look inside the scaffolding.
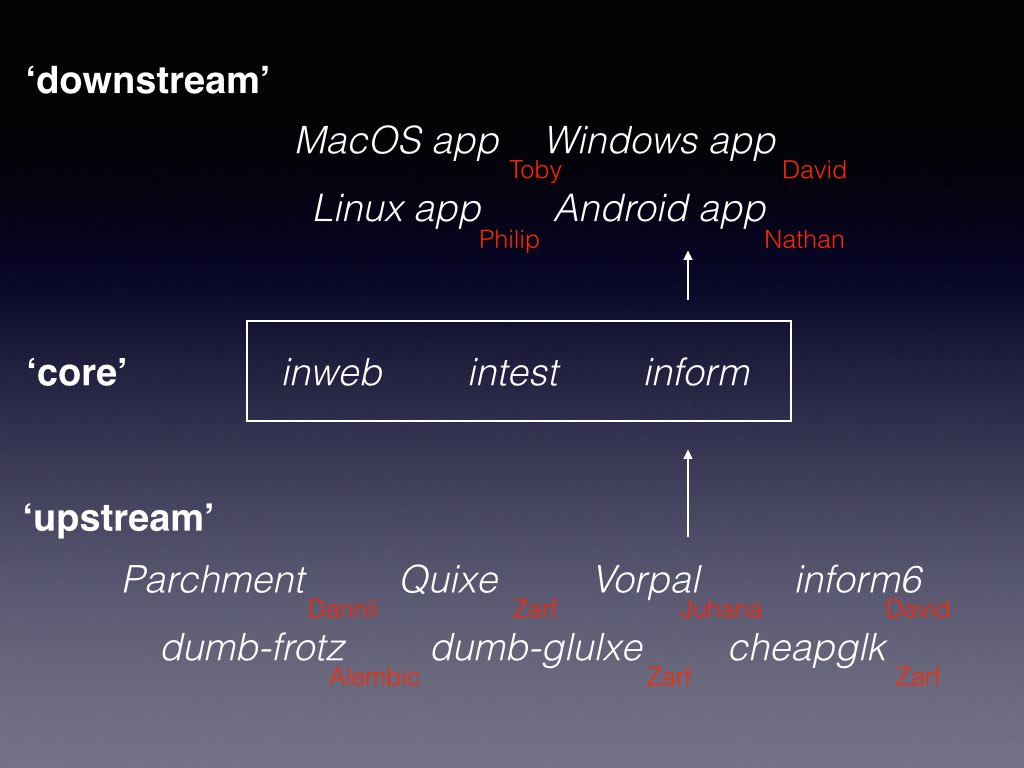
Inform as delivered to its users, via the Mac App Store, or direct download, or however they receive it, is a composite. This simplified diagram shows how code flows through various repositories. I am author and maintainer only of “core Inform”; the names in red are other team members. It took around three months of work to migrate the project to Github, and over 100 commits just to construct a cross-platform build mechanism. The two key decisions were: to have multiple repositories, or just one — I compromised on three; and to use git submodules, or not — I ended up deciding not.
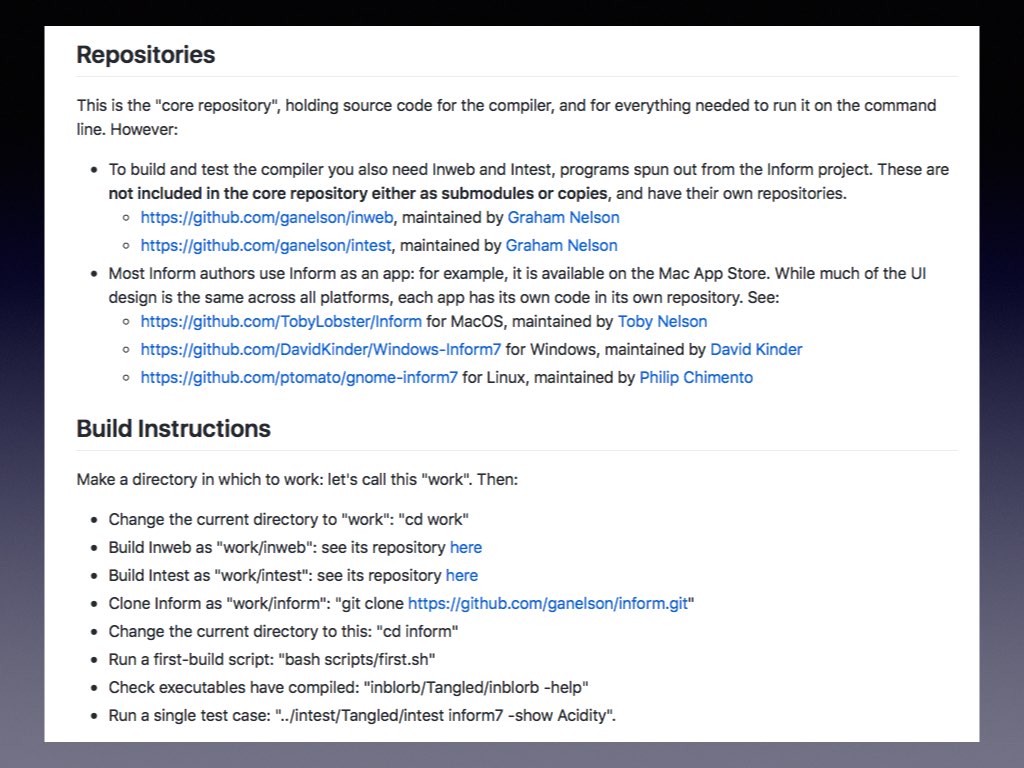
To get started you need to clone and build three tools in turn: inweb, intest, and inform, so the instructions run for a few lines. But only a few, since Inform has no dependencies on third-party code. You need a modern C compiler, ideally clang, but gcc will do; and you need basic Unix tools. But that’s all.
Core Inform is written in ANSI C, properly speaking C99. That was the first decision I took, in 2001, and it was the wrong choice. I had my reasons, but C++ would have been better for the heterogenous tree structures you need inside of compilers. I feel much happier about my other early decision, which was to adopt literate programming.
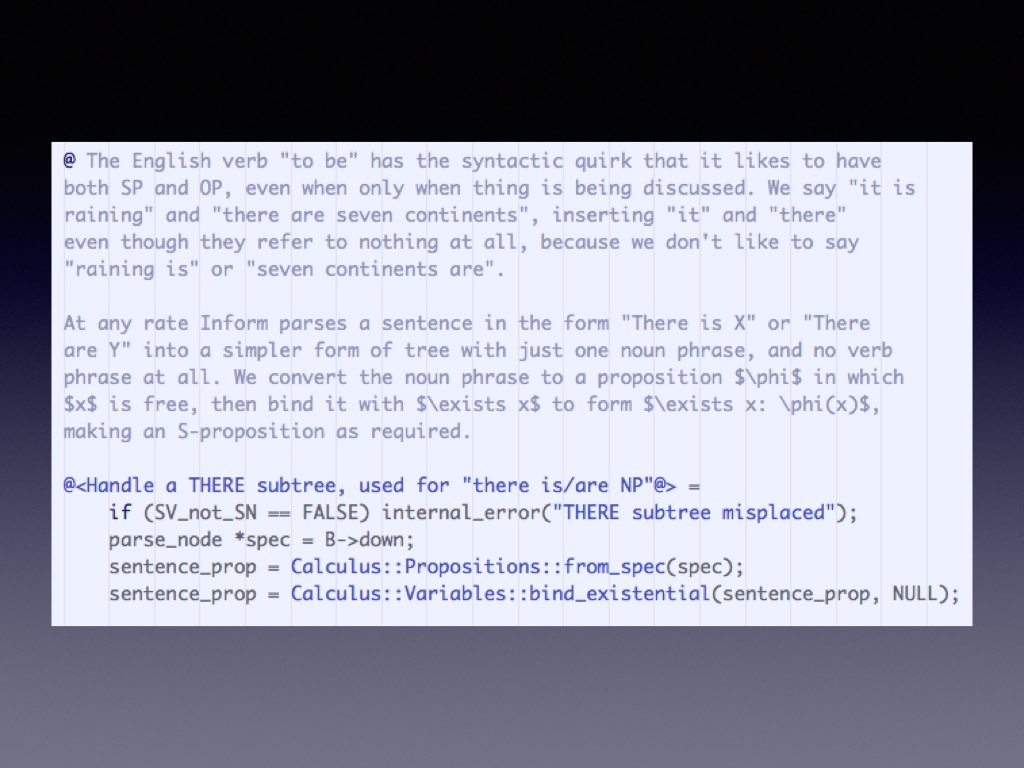
Literate programming was invented by Donald Knuth in the 1970s: he was responsible for the slightly insulting name, as if all other programmers are illiterate. The idea is to write a program like an essay, with a narrative, so that its source code can be read by humans as well as computers. This is not just about commentary: it’s about making long or complex functions more comprehensible. Here’s the function at the heart of Inform, which glues sentences together from their subject and object phrases.

Note the “paragraphs”, shown here in darker blue. These then have expanded definitions, further down in the file. But the idea is that you can see what happens at one glance. In orthodox programming, you’d end up writing a lot of one-use functions with a lot of awkward names and parameters to achieve the same end. And here’s the definition of “Handle a THERE subtree”:
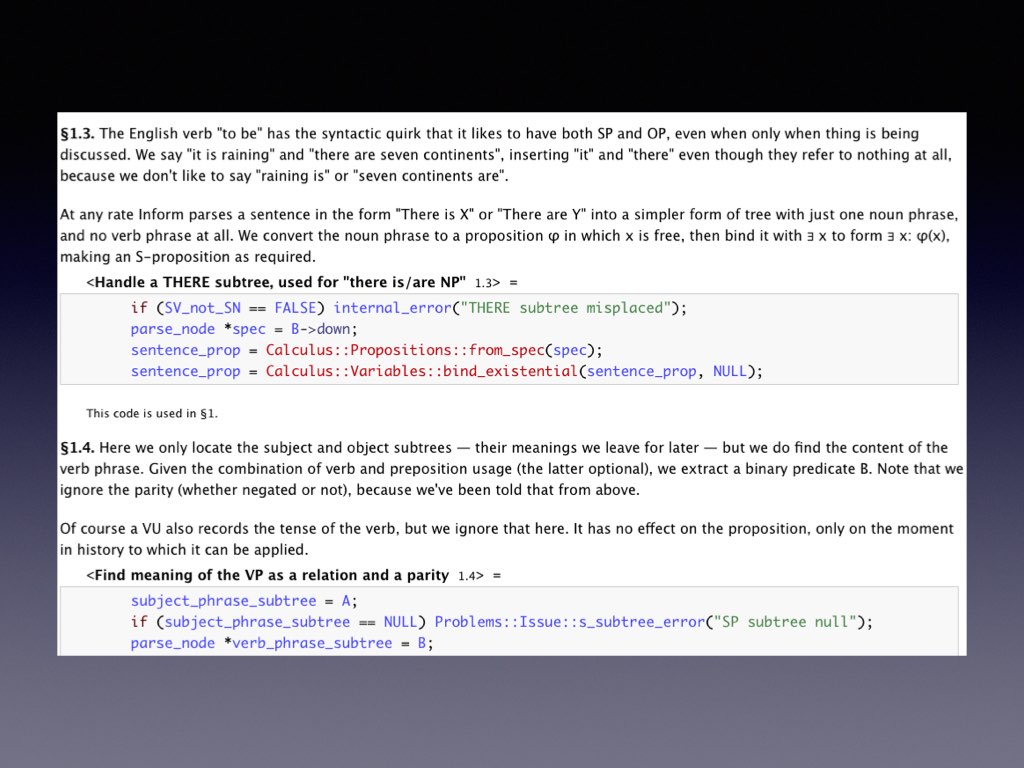
The necessary preprocessing to turn this into something which can compile in a C compiler, a process called tangling, is done by a tool called Inweb. This does other helpful things too: it removes the need for C header files and for predeclarations of functions, it adds a little modularity to C, and so on. Besides tangling, Inweb also “weaves” code into a human-readable form, such as a web page. Here’s the same passage in its woven form:
Literate programming is not a popular choice today. The canonical primers on software are respectful but basically tell you not to use it: “Code Complete”, for example, or “The Art of Unix Programming”. It failed to catch on for several reasons: most programmers do not like to write essays. Most code has a short shelf life anyway. Commentary in code is out of fashion these days, and some coders even consider it harmful.
But literate programming wasn’t as completely rejected as it might seem.
Some of the ideas do live on, especially in teaching environments, and they strongly influenced Inform’s design. LP continues to be used in some theoretically difficult software, such as the Axiom computer algebra system. The Axiom project adopted it because of their goal to keep the code understandable over a 30-year timescale.

I think they’re right to think in those terms. Inform is already 26 years old, and even Inform 7 is over 18.
Still, it must be said, proper literate programming is now hard to practice even if you want to, because there are no really first-rate tools for it.

The 1970s tools, written by Knuth, contain both hard size limits and heavy restrictions. They can’t really be used any more. When the World Wide Web arrived in the 90s, there was a second wave, of which the best are noweb and funnelweb. Noweb is still sometimes used, but these tools went to the opposite extreme, being too general-purpose to add much value. For what it’s worth, Inweb is being given its own repository independent of Inform, so at least there’s now another option out there. Quite a lot of work has gone into it over the last few years, so if you’ll forgive an Apple-style slide of features I won’t talk about:

Above all, it handles modules of code, which in effect are libraries for sharing across multiple projects. The inweb repository contains one module in particular which was built by collating together all of Inform’s lower-level support functions, thus moving them out of the main compiler. This module is called foundation:

Foundation provides the higher-level features you get in a more modern language, and that makes coding in C much more bearable. It also abstracts away issues like 32- versus 64-bit, and POSIX versus Windows file-handling and threading. All of Inform’s tools are now built on foundation, including inweb itself, which is why foundation is shipped in the Inweb repository, not the Inform one. Most notable here is the foundation provides flexible-sized strings of UTF-16 Unicode text; that was a dramatic change, and it took about six months to strip out all ASCII C strings out of Inform in favour of these.
The other sidekick repository is intest. This was once a hacky script tied entirely to Inform, but it’s now a general-purpose tool for testing any command-line software, so it too is offered independently. Tests follow multi-stage recipes, written in a language called Delia. If I were American, it would be called Julia.
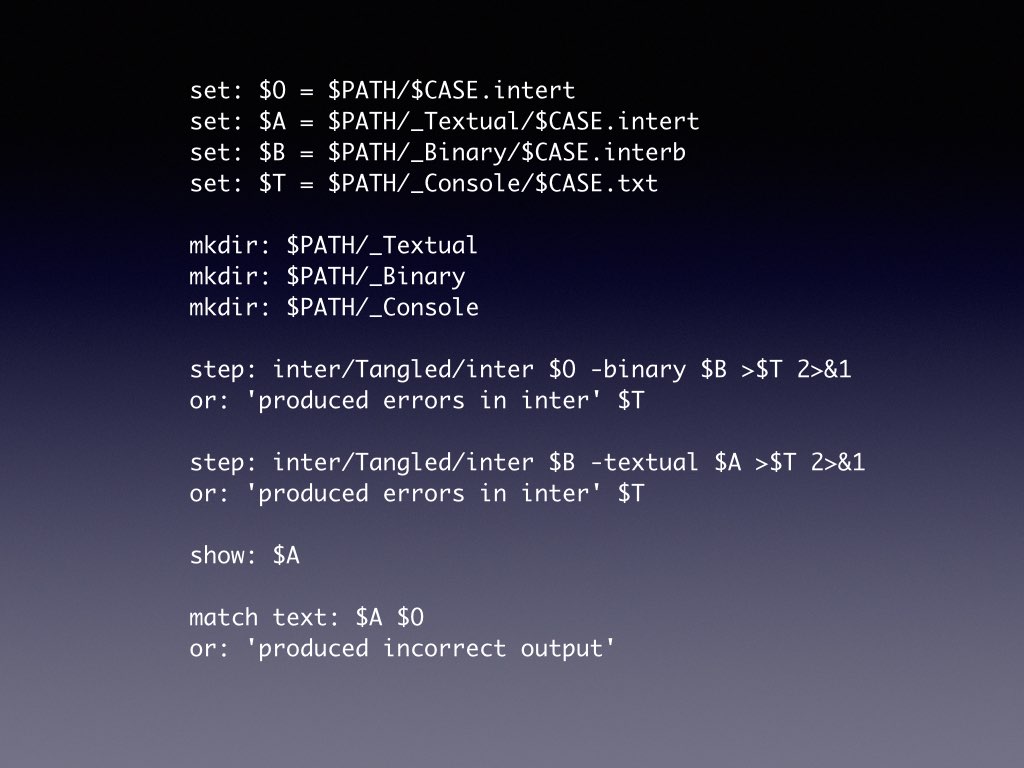
Intest is used for testing all of the Inform tools, but its main party trick is to spread a suite of 2000 tests of Inform 7 across all the available cores on a modern computer. Each test only takes 3 seconds, but with 2000 tests and only 3600 seconds supplied in every hour, you really want to run them in parallel.

So much for the two sidekick projects, Inweb and Intest. Those are only two of the nine Inform command-line tools. The other seven are all inside the inform repository. The list as a whole looks like this:

These vary greatly in size. Indoc is 7000 lines, but Inform 7 is 170,000. They can all be used at the command line, outside of the familiar user interface apps, and they all follow standard Unix conventions. They also all have manuals.
My final structural change was the largest of all: I wanted to make Inform more useful. I began by asking myself a basic question: how do we make a program more useful, and widen its range of usefulness? Well: a program turns an input into an output, so you generalise the input, and you generalise the output.
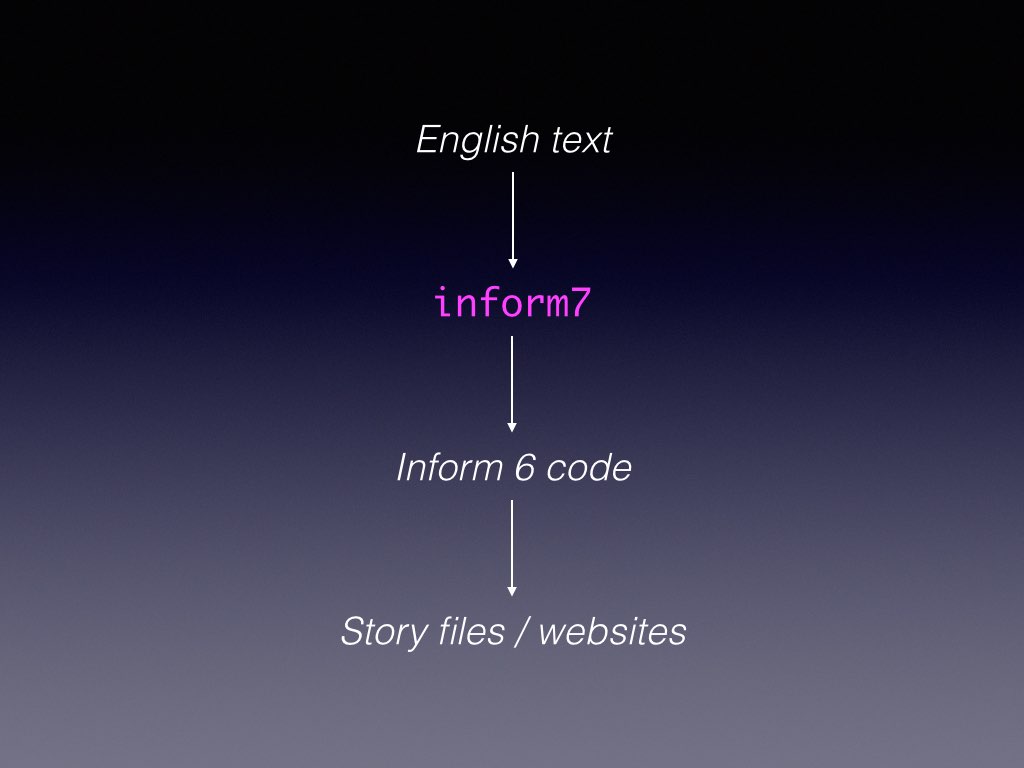
This shows the input and output for Inform, which in some sense turns English language into interactive situations, via a lower-level language called Inform 6. Here’s what generalising the input would look like:
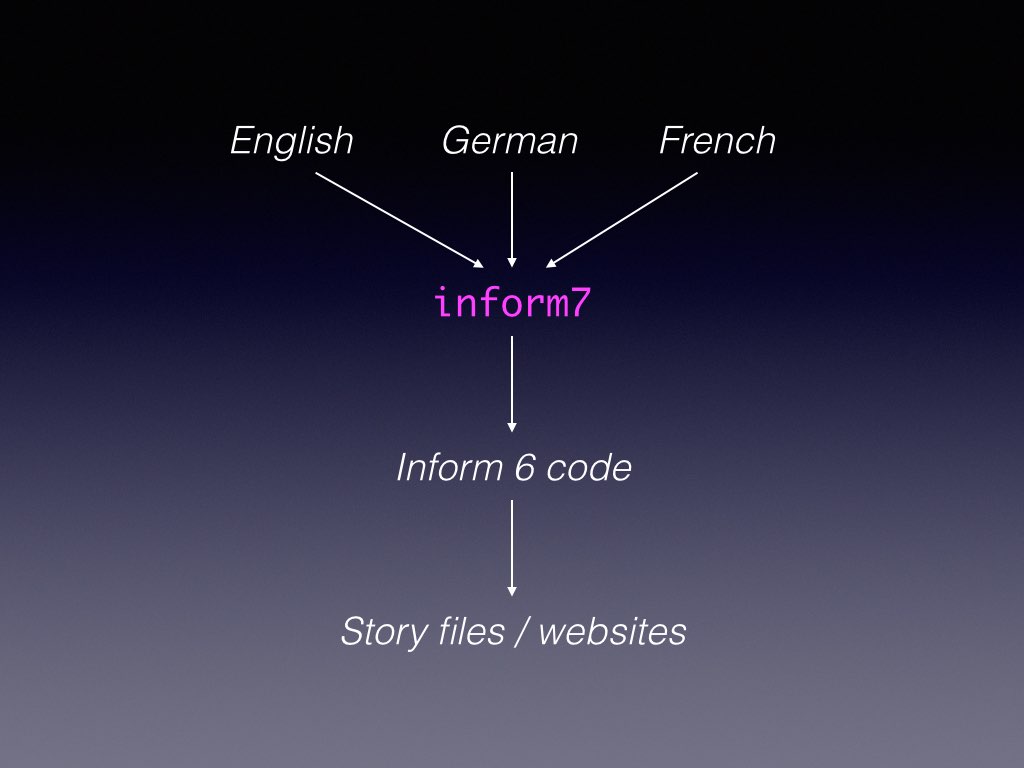
A great deal of work has gone into this. You can supply verb conjugations and inflections and natural-language grammars as alternatives to English, and so on, but it’s still immensely challenging. For one thing, Inform’s output is not just the code it produces, but also the Index and the problem messages. There are partial mechanisms for localising them, but we’re a long way from this dream being a reality. Open-sourcing should make it easier for people to work on this area.
So much for generalise the input; now, generalise the output.
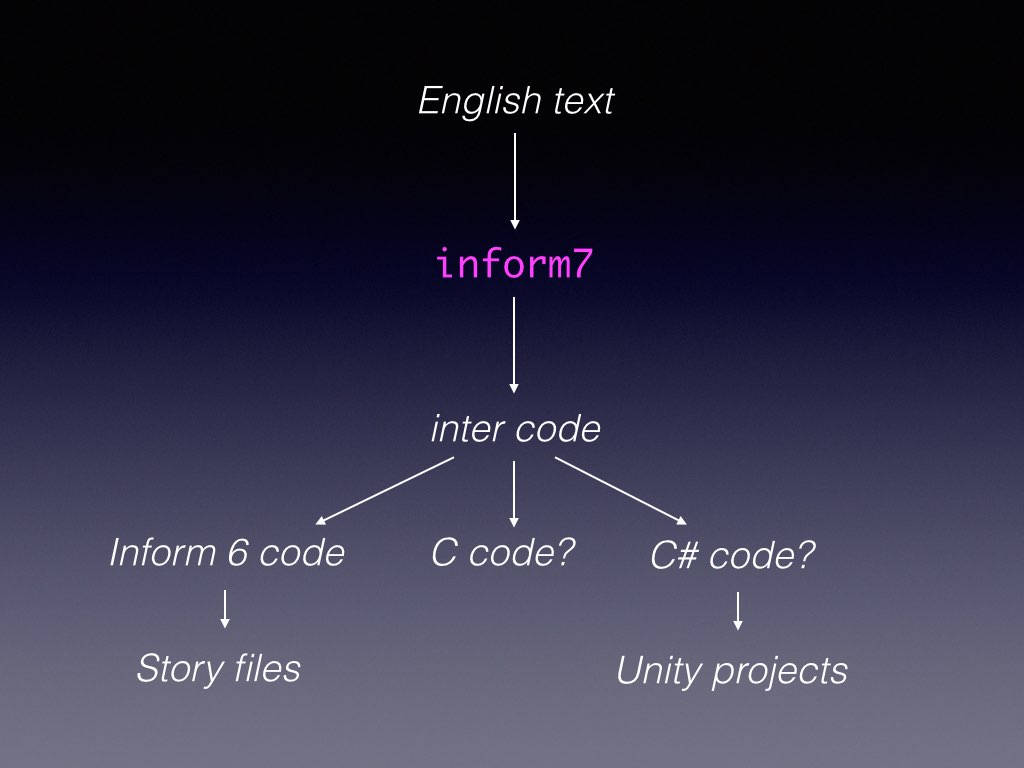
This is the main change I’ve made. The Inform compiler has an entirely new back end, which generates an intermediate-level code called “inter”, and only then code-generates that into I6. (I6 is the Inform 6 language, which is much lower-level.) But Inter doesn’t have to be converted to I6: all kinds of other possibilities are now open.
Inter is handled by a pipeline somewhat influenced by the design of LLVM, and pipeline stages are easy to add. This makes it easy to experiment with optimising the code. For example, one evening I wrote a peephole optimiser to remove unnecessary Inform 6 labels: it took only a page of code, and reduced the quantity of Inter generated by about 2%. Similarly, a redundant code elimination stage reduces the size of typical story files by about 20%.
Until 2015, the way that Inform generated code was to write out a textual file in Inform 6 syntax, which I’m going to call I6 from now on. That was very fast, but meant that low-level compilation code was spotted all over the compiler.

That may seem surprising on the face of it. You might reasonably think that the functions produced by Inform correspond to the rules that it finds in the source text — one rule makes one function. And Inform does indeed make each rule into a function; but that’s only one out of the 91 different sorts of function that it needs to make for different purposes.

Suppose our example rule contained:
if a battery compartment which is part of the machine contains a battery (called the power source)
Inform tests that logical proposition with another function.
Well, there are 89 more needs like that, and there are hundreds of run-time data structures, mostly arrays. So it wasn’t a small undertaking to generate Inter instead of I6.
But I’m relieved to say that that project is now complete. For over a year, Inform generated hybrid forms of Inter containing raw I6 expressions (called globs) and raw I6 function bodies (called splats). When I spoke at the London IF meetup in 2018, I said that “it was a big day when Inform no longer generated any globs, and it will be a bigger one when it no longer generates any splats”. That day was 6 May 2019.

So what is Inter? Well, it’s an intermediate-level description of the program, which can exist in three forms: in memory, as bytecode; in a file, in binary form; or in a file, in textual form. For speed, Inform keeps Inter as bytecode in memory at all times, but you can add stages to the pipeline to write out the current state to a text or binary file. The inter command line tool faithfully converts between these three forms.

Inter is low-level, and therefore verbose. You wouldn’t want to write it by hand, though you can. A typical 1000-word source text — the example “Witnessed” from the Inform documentation, which is where these batteries come from — currently generates 285,606 instructions of Inter. That’s because of the enormous amount of supporting code needed to manage the world model, and to parse commands at run-time. Those 285,606 instructions then generate 81,736 lines of Inform 6.

This shows how a very small fragment is processed: a single line of Inform becomes a chunk of Inter and then some Inform 6.

Inter code is hierarchical: it is, in effect, as much like a final parse tree as a stream of assembly language. At the highest level, it’s a hierarchy of “packages”, each of which has a type. At the top level is main, which holds a number of packages of type “_module”. Some modules derive from natural language Inform code in a direct way: each extension leads to a single module, and the “source_text” module is what the main source text leads to. For example:

That little source text leads to a package of Inter that fits on a single screen. It’s in small type, but it’s 30 lines, not 290,000. As you might expect, this defines two physical objects in the spatial world model of a little interactive fiction. If we get rid of the details:

As this demonstrates, the hierarchy conveys something quite semantically rich, and enables us to locate resources within what may be a large tree of Inter.
If I run the Inter command-line tool on the output from Inform and use the -inventory switch, it will be able to tell me that there are two instances created in the source text.

And it can also tell us exactly what the different extensions bring to the party; here are some more instances, kinds and variables.

Each package is a little self-contained world, with all its references to other packages being made explicitly in a symbols table. Anyway: that’s enough to get the idea; the whole thing is documented in the Inter manual.
As a brief aside, though, I do want to mention the biggest challenge in doing all of this. The Inform 7 language contains some low-level features intended for use mainly by the Standard Rules, allowing you to define phrases using I6 code.

What are we to do with this I6 content? One option would be to rewrite the Standard Rules in some entirely new syntax based on Inter, and to rewrite the template files in Inter. Both would be problematic, and anyway many other extensions also use I6 phrase definitions, even if end users mostly don’t.

The solution is a technique called “assimilation”. Inform now contains an I6 decompiler, which converts it into Inter code. That’s not many words to say out loud, but it took quite a lot longer to get working. The practical effect is that although I6 syntaxes are still read in by Inform 7, they are used purely as a concise notation to express Inter. At present, that Inter is code-generated back into I6 again, thus completing the circle of life. But later on it may code-generate into other things.

The Inform documentation example “Uncommon Ground”, right at the very end of the manual, was very much the worst case scenario. It doesn’t look natural-language at all, because it shows a low-level way to define a multi-part text substitution. Those four phrase definitions collectively make an I6 switch statement. But not one of them is a syntactically valid piece of I6 on its own. Fragments like this are the hardest to assimilate.
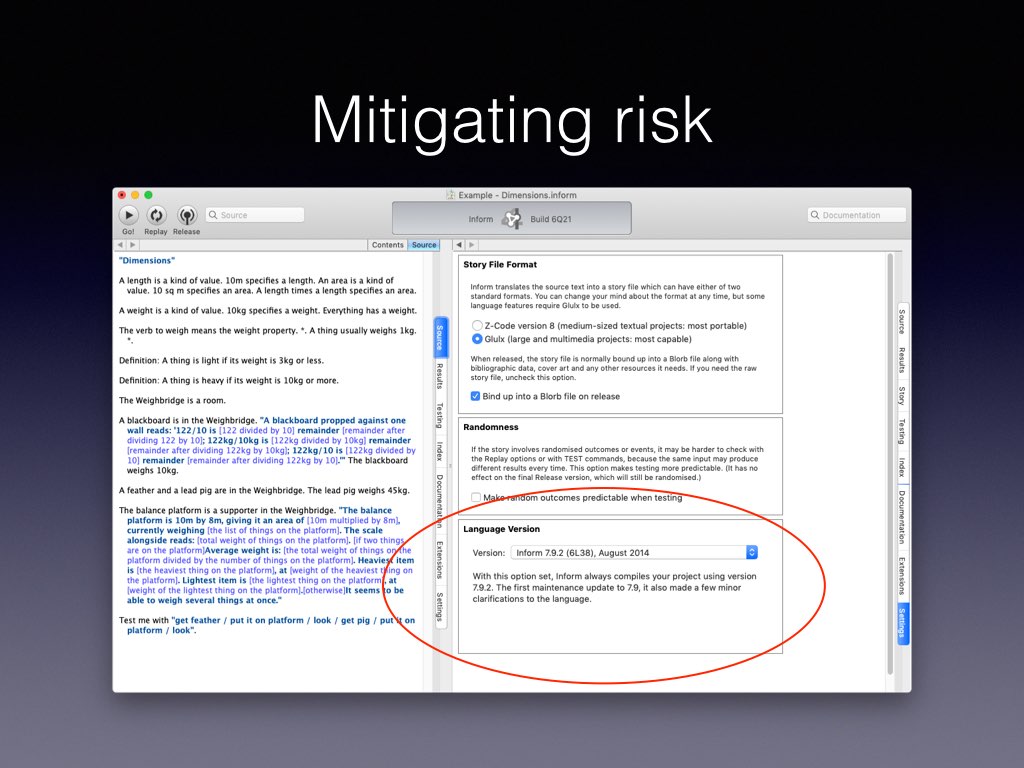
Well, end of aside. I think it’s apparent that the 2015-2019 rewrite has been pretty dramatic in scale. That adds risk: people need Inform to carry on working as it should. To mitigate the risk, there’s a new Settings control in the app, allowing the version of Inform to be changed.
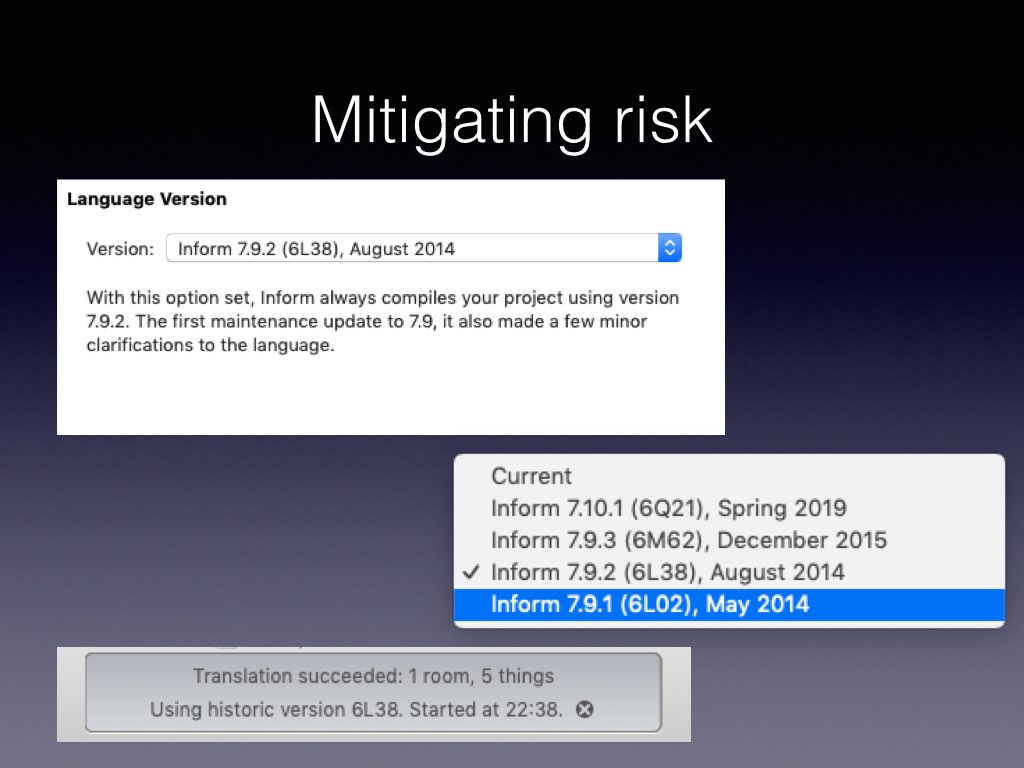
Turn it back to the 2015 version, and you get the 2015 compiler, template and extensions. We will support at least three previous language versions before the current one, and we’re working on going further back, for archival purposes.
So, then, that’s what has been done. It’s nearly there: I’m only a few momths away, and the next public release will certainly be in 2019. Simultanously with the next public release, the Github repositories will all be made public. I want to spend the rest of my time on open-sourcing, and where it takes us.
To recap, core Inform was migrated onto Github in December 2018, and by around March we had the new build process sorted out reasonably well. I’m confident now that it will be fairly easy to pull, to build, and to fork. The structure will be fairly sound and that code will, despite the complexity of what it does, be fairly readable.
But what then? The words “open source” sound simple enough, but they stand for quite a range of social practices. To begin with, there’s an actual contract: the licence.

This I think will be uncontroversial. The Artistic License is at the free end of the spectrum, closer to MIT than to the GPL. It’s like a software version of Creative Commons Attribution, where your only real obligation is to credit the authorship of the original. If you fork and change Inform to a different language, you’re obliged to call it something else. Two additional grants will be made, one clarifying the status of code output by Inform, one clarifying the license for Inform 6. No existing freedoms will be lost.

But a license is only the start. There will need to be policy on a host of uninteresting practical questions. What bug-tracker to use? Do we stay with Mantis? Who will manage bugs? Will release downloads be hosted at the core Inform GitHub pages? What happens to the existing inform7.com? Will we offer app downloads on unstable branches, or just for public releases? How do we cope with increasing issues on MacOS to do with code-signing, sandboxing and notarization?
[Discussions after the talk also led to the question of copyright: on some projects contributors assign copyright, and on some they don’t. For Inform the consensus was that it’s best to have a single copyright-owner, currently myself, so that we have the option to transfer this copyright to the Interactive Fiction Technology Foundation at some later time. Because of that, contributors will probably need to assign copyright.]

A thornier question is: what is the gatekeeping process for new features?
In most open-source programming languages, there’s a proposal system, and a set of social practices whereby people debate the merits, try out an implementation of something new, and then decide whether it’s in or out. As the recent affair of the Go package manager shows, it’s all too easy for the creators and the contributors of an open source project to misunderstand each other entirely. I think it’s best to set out expectations from the beginning.
I’m not open-sourcing Inform as a way of walking away: I intend to remain its overall designer. Projects which lose their leaders, for want of a better word, tend to stumble because there’s no oracle to go to for a ruling. Even in languages where the creator has ostensibly ceded control — Python, Swift, or Perl — the creator generally remains a power behind the scenes. I think it’s better to be up front about that: I’m going to have the last say on what goes in.
More positively, though, I hope to publish a document giving a list of general areas where volunteers might take a look. It’s probably good at first for people to contribute bug fixes and get their bearings in the code, but here are a few possible examples of more ambitious projects.

Inform is quite often used in the games industry for mock-ups of interactions: it’s a way to storyboard the sort of interactivity which will eventually be achieved by other means. But what if Inform could actually be used directly to provide final implementations inside games? In other words, as a middleware component in, for example, Unity? I’d be interested in working with a game developer who wanted to try that.

Nowadays most programming languages would benefit from package managers, and so would Inform, though in our case it would be an extension manager. We have that, in a primitive form, as the Public Library in the apps. But it would really be better to have a clearer idea of versioning, and to be able to fetch extensions from appropriate branches in public git repositories.
At present Inform story files are played more often in browsers than in interpreter apps. That means they are interpreted in JavaScript code by a program called Quixe. It might be interesting to compile from Inter directly to Javascript, in a way which incorporates large chunks of Quixe. Other target languges might also be interesting: the visual art language Processing, for example. Imagine using Inform-style natural language to describe the art you want to make.

Lastly: There’s currently no Inform app for iOS, and it would be very nice to have one. Inform for Android showed that people may actually quite like the experience of Inform for mobile; especially for something like an iPad with a keyboard case.

Well: so having begun with a slide of Boston Commons in Spring, I leave you with a slide of Oxford in Autumn — a movie-style Coming Soon poster for the open sourcing. Inform 1 was created in the sandstone building just behind the junction of Longwall Street, in the upper left. So that is where it all started, and this is where I will now end.
