Narrascope 2022 talk
This is a talk and slides from Narrascope 2022, held online in July 2022. It completes a trilogy — I also spoke at Narrascope I and Narrascope II. I’m grateful to the IFTF, and particularly to Judith Pintar and Andrew Plotkin, for arranging the opportunity.

Inform is a programming language based on natural language and especially aimed at the creation of interactive fiction. In the past, that’s been command-parser IF, a vibrant art form which will continue to surprise and delight us into the future, but it’s only one of Inform’s future use cases.
This is a talk about where the Inform project stands now, how it will develop, and what new features are coming on the near and farther horizon. As I go on, I will get more speculative, and I’ll try to make each five-minute segment of this talk more interesting than the previous one. But that means pacing myself by starting with some boring preliminaries.

This talk is not a report back on past work, but perhaps you’ll allow me a brief “Previously, on Inform…” segment up front, especially as this is my third Narrascope talk in a row.
Inform is a programming language. It has a compiler which does the sort of thing compilers do. But there are several ways in which it is unusual.
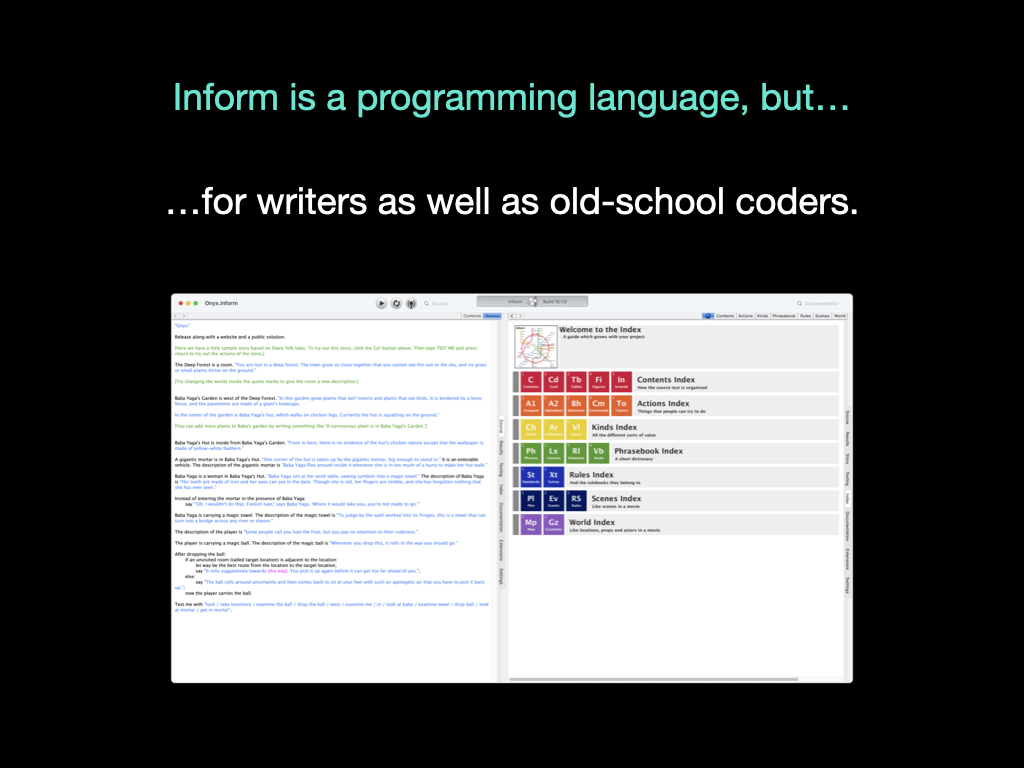
Firstly, most users experience it as an app or a web service, and their workflow is more like writing than coding. They may never use a command-line, or a build tool, or a text editor. What I’ll call the “apps” – Inform for MacOS, Windows or Linux – hide all of that. This is an explicit goal of Inform, so the apps are an important part of the project.
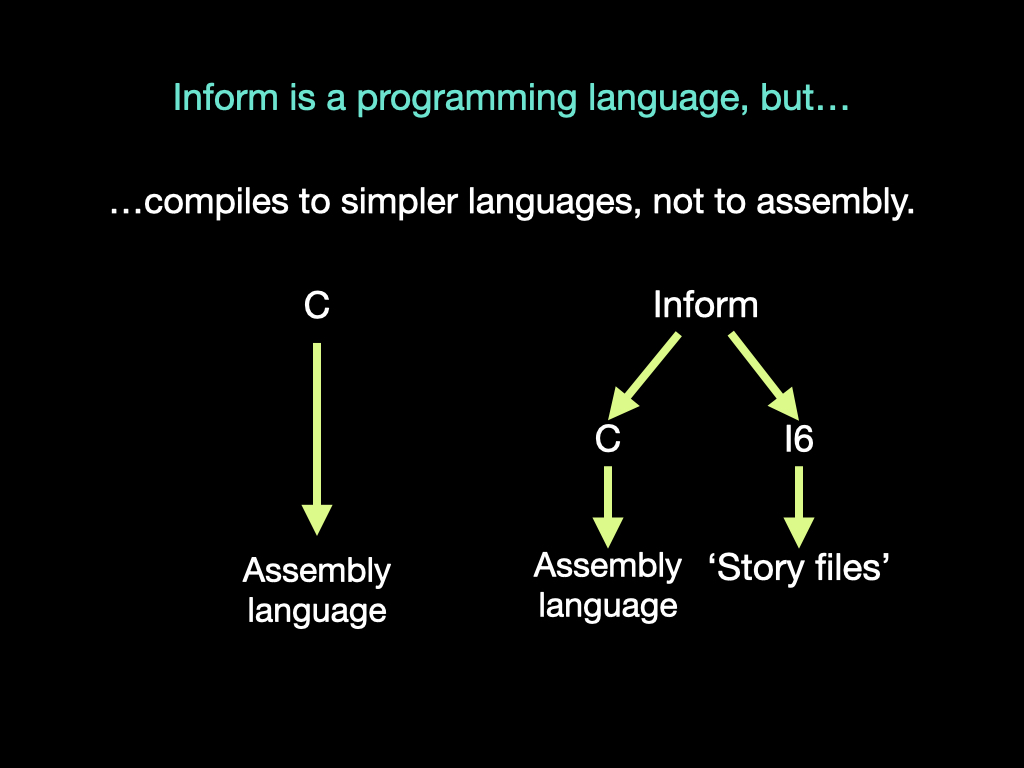
Secondly, Inform does not compile all the way down to assembly language. It compiles to a human-readable but low-level program which a further tool takes the rest of the way. That’s not unique (the functional programming language Haskell goes via C, for example), but Inform is unusual in supporting multiple target languages - currently two of them.
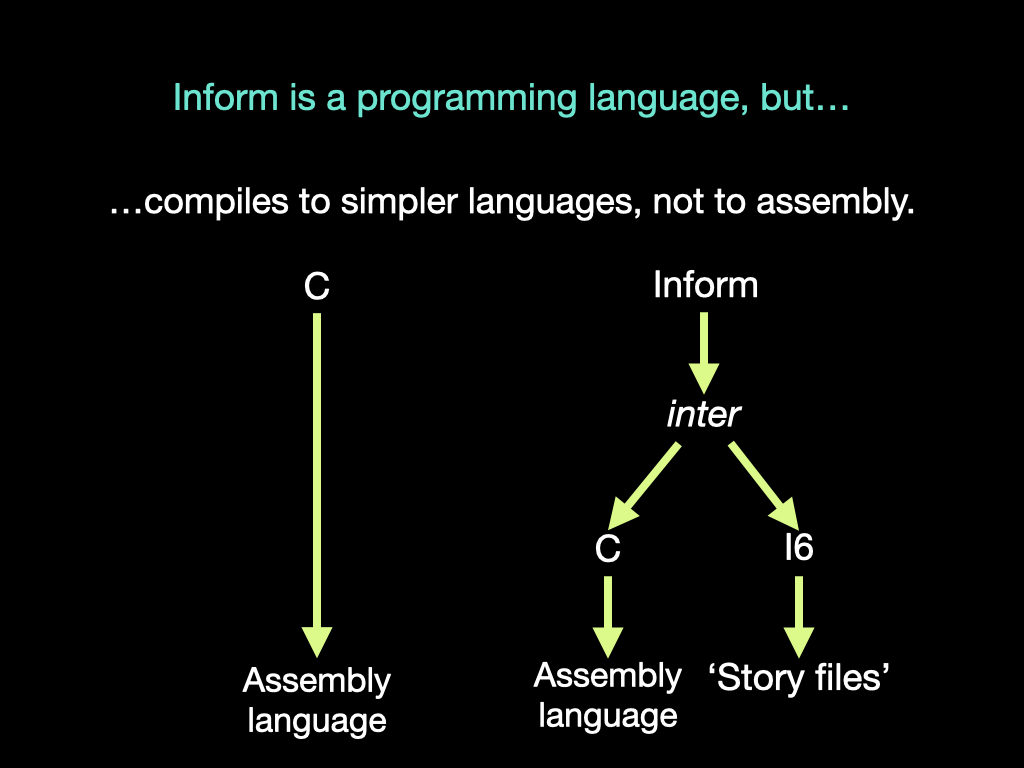
At Narrascope I, in Boston, I sketched out how a new intermediate representation inside Inform called “inter” might make this possible some day. That has all now happened.

Thirdly, in Inform, structures in the source text do not correspond well to those in the compiled code, and small often makes large. Even a short source text like “The Laboratory is a room.” generates what amounts to a simulation engine sitting on top of a miniature operating system. That’s typically about 81,000 lines of output, and the concept of the Laboratory is not easy to locate in that output. At Narrascope I, I used the word “kit” in public for the first time: a kit is a pre-compiled block of material used by Inform to put these quite complicated structures together. Kits are written in a low-level language called I6, compiled to Inter, linked with more Inter coming from the Inform source text, and then translated down to either C or I6 again. As I explained this happy scheme in Boston, at the back of the auditorium Andrew Plotkin was kind enough to mime his head being blown off. But it all now works, and Andrew’s head is still on.

A fourth way in which Inform is unusual has gone. It was closed source, but I announced at Narrascope I that I was nearly done with refactoring and rewriting, and would soon be ready to open-source the language and all its tools. At Narrascope II, online during the hardest summer of the pandemic, I then said that I was getting closer, but conspicuously gave no date. I also spoke at both Narrascopes I and II about what’s called literate programming, which I wanted the publication of Inform to make a contribution to. I won’t talk about that further today, but it remains something I care about.
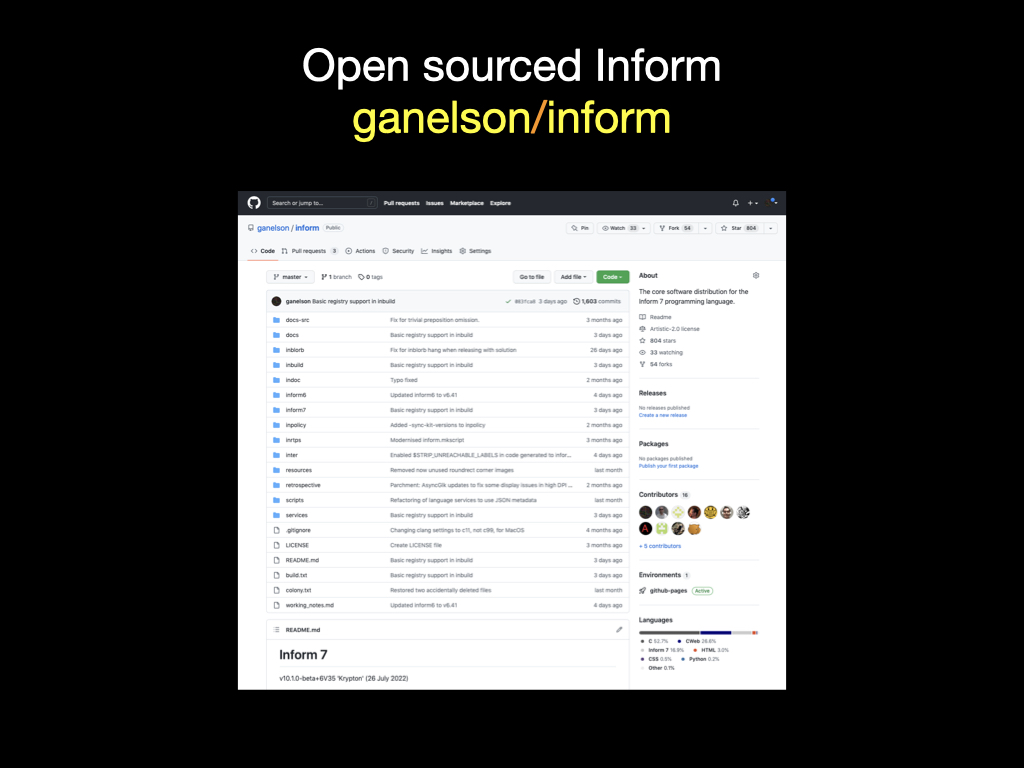
The git repositories for Inform went public on 28 April 2022, Inform’s traditional birthday, and I’m grateful for the welcome it has received. The core repository is up to 806 stars now, which makes me feel very important — I mean, the American flag only has 50 — until I calibrate that by looking up Python, 47,000, Swift, 60,000, and Rust, 70,000. The last mouse-click after five years was a surreal moment, but also a huge relief. I could now be struck by lightning and my life’s work wouldn’t be lost. Well, I realise that hoarding stars, and talking about my life’s work, are both vanity. But it was quite an emotional moment.
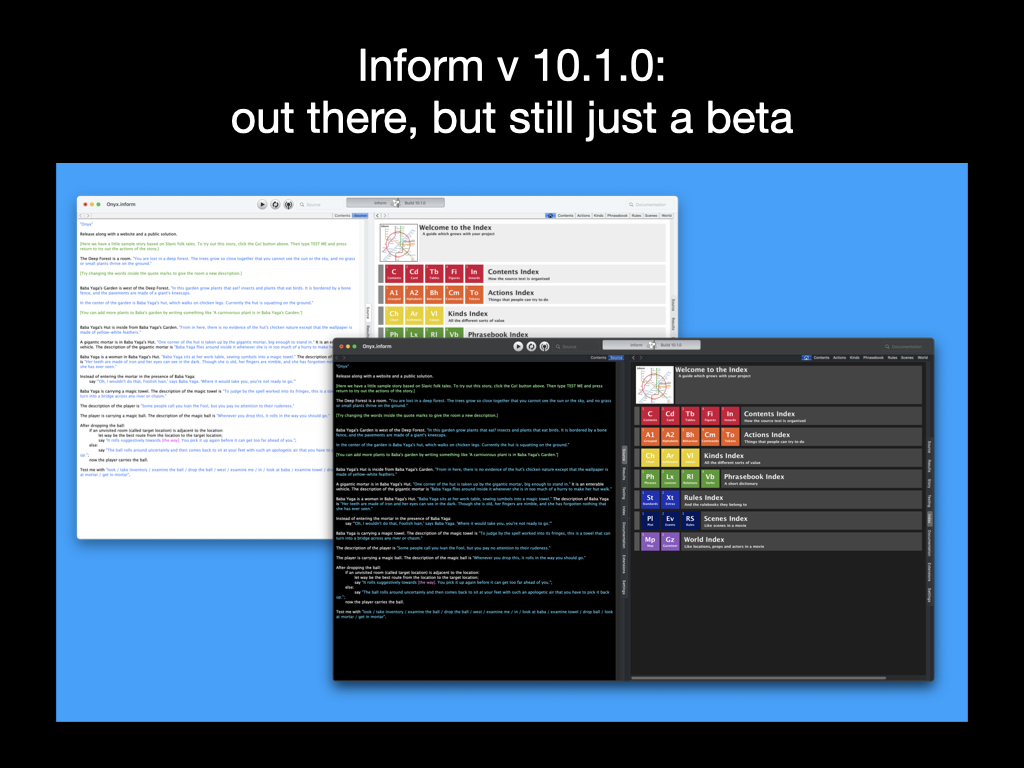
That was three months ago. What we had then was a beta of the next proper release of Inform. People are already running these betas of version 10, on the command line, or in previews of the Windows, Linux or Mac apps, or on web services like borogove.app, or even in Docker containers or Github Actions. Here’s the new version of the Mac app, running on MacOS Monterey, in both Light Mode and Dark Mode - Dark Mode is new. As of today, this Mac beta is available at Toby Nelson’s github pages. Time was when you compiled a program and then other people ran it, but it’s now a complicated business shipping an app for a consumer operating system. Toby’s app is, I quote, “hardened, entitled, sealed, signed, provisioned, archived, imaged, notarised, and stapled” but not yet “sandboxed”. I salute Toby, and David Kinder and Philip Chimento on Windows and Linux, for coping with this world.

A new feature here is a nice Web service giving a calendar of upcoming community events, which I hope will connect users with the excellent IFTF Foundation, our hosts here at Narrascope.
So the genie is out of the bottle. We must now bring the beta period to an orderly end, and make a proper release of 10.1: we’re very nearly there, with just some Public Library tidying-up left to sort out. It’s time to have procedures for how to manage releases from here on, so here goes.

Inform is developed in public. Command-line users comfortable with git can always get the very latest state. But that potentially means endless different versions of Inform out there in the wild. To clarify this situation, all versions are numbered, and we will distinguish between “release” versions, which are ready for public use, and “unstable” versions, which are not.
“Release” versions have simple version numbers in the shape X.Y.Z. As I mentioned, we’re coming up on 10.1.0.
“Unstable” versions are commits of the software between releases. You can always get these from Github, but you probably shouldn’t. Unstable versions have much longer version numbers, containing an -alpha or -beta warning. For example,
10.2.0-beta+6V35
This would be an unstable version working towards what will eventually be 10.2.0. The +6V35 is a daily build number, which most people can ignore. Actually that’s not true. Everybody can ignore it.
Going forward, we will mostly not provide binaries of the apps for unstable versions - only for releases. Right now there are downloadable apps of the 10.1.0 be unstable versions of 10.1.0 available on all three platforms, but we’ll be taking those down as soon as there’s a proper release to provide instead.

Two minutes which will make sense only to developers who use the source control system “git”. In the core Inform repository, active development is on the “master” branch, at least for now. That will always be a version which is unstable. All releases will be made from short branches off of “master”. For example, there will soon be a branch called r10.1. This will contain as few commits as possible, ideally just one, which would be the actual release version of 10.1.0. But if there are then point updates with bug fixes, say 10.1.1, 10.1.2, and so on, those would be further commits to the r10.1 branch. Later, another short branch from master would be r10.2.
Releases will be tagged with their version numbers, so the commit representing 10.1.0 will be tagged v10.1.0. These will be presented under Releases in the usual Github way, from the column on the right-hand side of the home page. We expect to provide the app installers as associated binary files on those releases, though that won’t be the only place they are available.

As I say, all versions will have a three-layer number in the form X.Y.Z. A brief word on what this means. In a pragmatic, not quite strict way, this will be a semantic version number. For those who don’t use it, semantic versioning, or “semver”, is an Internet standard for how to assign software version numbers. See semver.org. Semver was created mainly for component parts intended to be used inside other people’s programs. (Inform extensions are like that, and now use semver.) In those situations, strict adherence to the rules is good. But for big umbrella-like systems, such as programming languages, strictly following semver tends to be unhelpful, because all that happens is that Y and Z are never used at all.
Here’s what I intend to try, and we’ll see how it goes. The three parts of the number X.Y.Z are called MAJOR, MINOR and POINT. My plan is:
-
if a release withdraws any significant functionality or syntax, or significantly changes how an existing feature works, the MAJOR number must increase;
-
if any functionality or syntax is added, or a not very significant change is made to an existing feature in a way which probably won’t cause anybody problems, the MINOR number must increase;
-
if the only changes are bug fixes, only the POINT number increases.
The weasel word here is “significant”. For example, 10.1 withdrew several forms of the Include (- ... -) syntax: that was a MAJOR change. But the proposed increase in precision of how Inform handles real numbers, which I’ll come it, is more like a MINOR change.

So let’s talk about some changes. Most major programming languages have a formal system of numbered proposal documents, hosted on their own public repository: for example, Swift Evolution and Rust RFCs.
In England, by the way, RFC stands for Rugby Football Club, which is not completely inappropriate to how compiler developers debate things. But really these are very helpful services for users of the languages who want to see what’s coming next, or want to have their say.
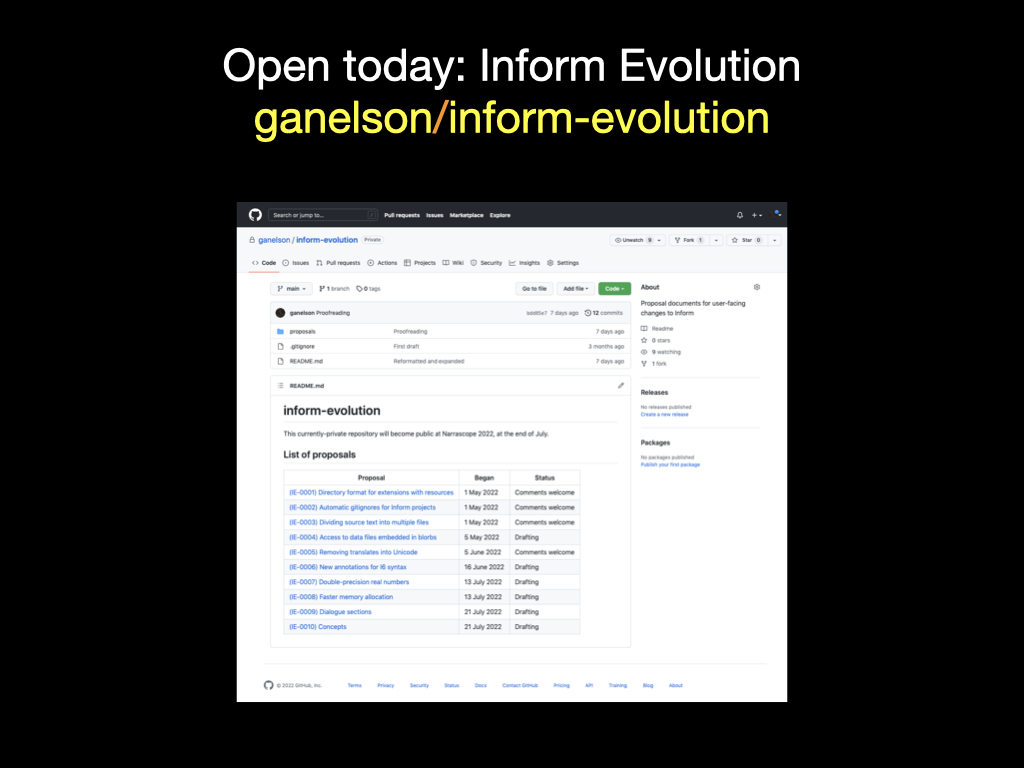
We are today making a new github repository public: inform-evolution.
“inform-evolution” holds similarly numbered proposal documents. At this stage, “proposals” are likely to be originated by the core Inform team, and will serve as both specifications of what we intend to implement, and as requests for community comment. Details may change and a few proposals may be withdrawn in favour of better approaches, but it’s reasonable to assume that when a potential change reaches proposal status then something like it will happen.

From now on, any language change large enough to cause a MAJOR or MINOR version number bump to Inform should result from a specific IE proposal. Proposal numbers will also be useful in marking commits. For example, a commit title like:
(IE-1234) Refactored kinds ready for meta-hyper-kind support
would be a signal that this is to do with implementing IE-1234.
For now, IE exists really to help the people already working on Inform to do some thinking in public. When Inform has been open-source for longer, we will need some process for users outside the core team to create IE proposals, and then to have a reviewing committee as gatekeepers. What I think IE will never be is a vague “wouldn’t it be nice to have something like this” channel - IF forum discussions are better for that.
“inform-evolution” currently has 10 proposal documents, IE-0001 to IE-0010, and those already give a good picture of what’s coming next. I’m going to take a tour, though not in numerical order. I’ll start by running quickly through a miscellany of small features, and then come to a middle-sized one, and finish with an enormous proposal.

What do I mean by small? Well, for example, IE-0005 is a change to make Unicode character names quicker to resolve inside the compiler. This will affect hardly anyone, but because it means withdrawing the hardly-used X translates into Unicode as Y sentence from the language, our rules say there has to be an IE proposal.

IE-0008 is also a small proposal, though in the end its effects may be large. It’s called “Faster memory allocation”, and proposes a low-level change to how the Inform runtime claims and releases memory. There are no language changes at all, so this change doesn’t strictly speaking need an IE proposal. But we’re giving it one anyway because it’s a significant piece of work, and just might change memory behaviour for a few existing projects.

In the same way, IE-0007 makes no language changes but doubles the precision of arithmetic used by Inform’s real number kind. This makes Inform real numbers similar to double rather than float in the C language. In particular, it means that any Inform number value can be faithfully promoted to real number and then rounded back to number without being changed by loss of precision, which can happen now. Again, this change in principle affects the runtime behaviour of existing projects, but (a) not very much and (b) almost always for the better. But it gets a proposal number even though it does not change the language as such.

IE-0004 is an example of a purely additive proposal, that is, it adds a new feature to Inform which won’t cause any existing projects to break. This enables Inform to take advantage of an existing feature of the “blorb” packaging format in which binary data files can be packaged up with a story file. This looks innocuous enough as a proposal, but it may turn out to be a Trojan horse for how file system access to binary files might be provided in future.

Another proposal, IE-0006, also lays a little groundwork. This is really a proposed standard way to annotate Inform 6 syntax code, which is a joint proposal with the maintainers of the Inform 6 compiler, David Kinder and Andrew Plotkin. Such annotations may be used in future for better control of how kits are linked, but IE-0006 doesn’t go there yet: it’s just preparing the way.

Next up, there are two small proposals aiming to help power users with large Inform projects put under source control. IE-0002 is a simple convenience under which Inform automatically makes .gitignore files to make it less of a fuss to start Git repositories which hold Inform projects.

IE-0003 is a mechanism for source text to be split up into multiple text files. This is intended as a drop-in replacement for what projects like “Counterfeit Monkey” are already doing, which is to have large numbers of what are supposedly extensions, but which are not really anything of the kind. For example, CM contains:
Include Act I Among Sightseers by Counterfeit Monkey.
[Book 1 - Act I Among Sightseers]
Well, clearly “Act I Among Sightseers” is not intended as an extension to the Inform language, for use by multiple projects. It’s the text of the material under the heading “Book 1 - Act I Among Sightseers”. Under proposal IE-0003, this can just become:
Book 1 - Act I Among Sightseers (see "Act_I.i7")
which has a clearer intention, I think, and means that no bogus extension needs to be created. The file Act_I.i7 then lives in the new Source subdirectory of the project’s Materials directory.
That completes the miscellany of small, harmless, nice-to-have but not especially exciting proposals. Now for a larger one.

IE-0001 changes and greatly expands the way Inform extensions are stored, and allows them to be bundled with further resources. This is a bigger deal than it first sounds.
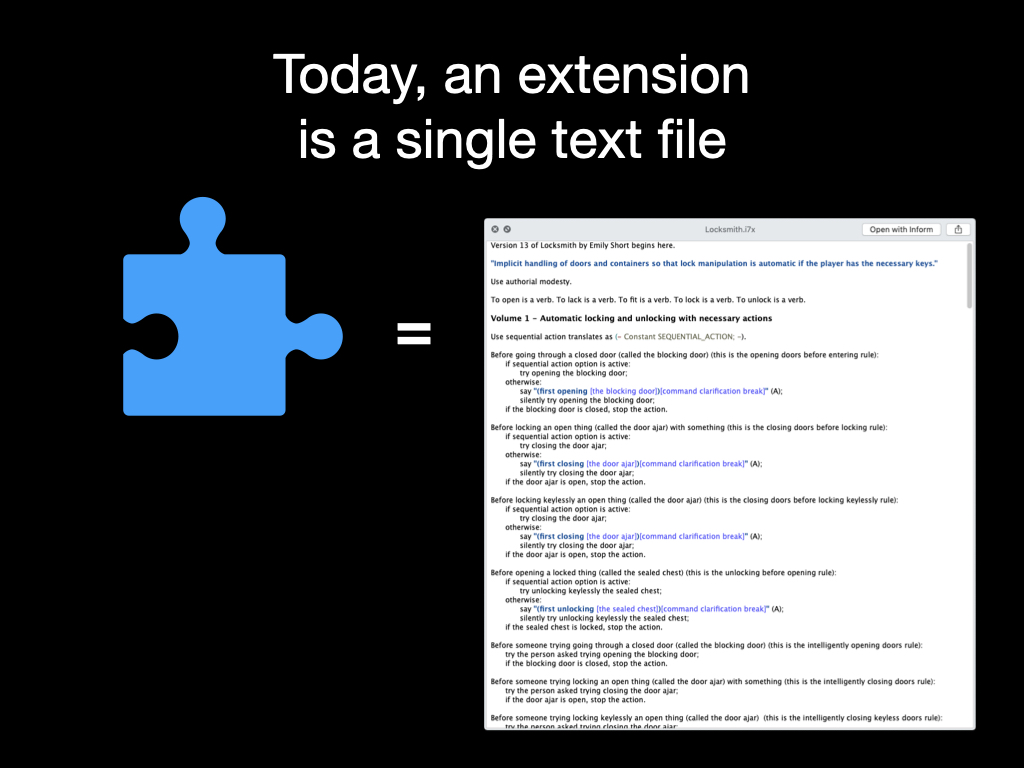
Since the beginning of Inform 7, an “extension” has been a single file, with a .i7x filename extension. The idea was that it would contain Inform source text providing new phrases, rules and so on for users to benefit from. Locksmith by Emily Short, for example, provided a tidy implementation of locks and keys.
After a time we found we needed extensions to be able to provide documentation and examples of usage and test cases.

Those had to be awkwardly crammed into the bottom of an extension file, because there wasn’t anywhere else. Similarly, an extension couldn’t be supplied along with associated low-level Inform 6 code, but this could be faked through heavy use of Inform’s Include (- ... -) sentence. The result is that extensions are already straining the limits of what can reasonably be crammed into one text file.
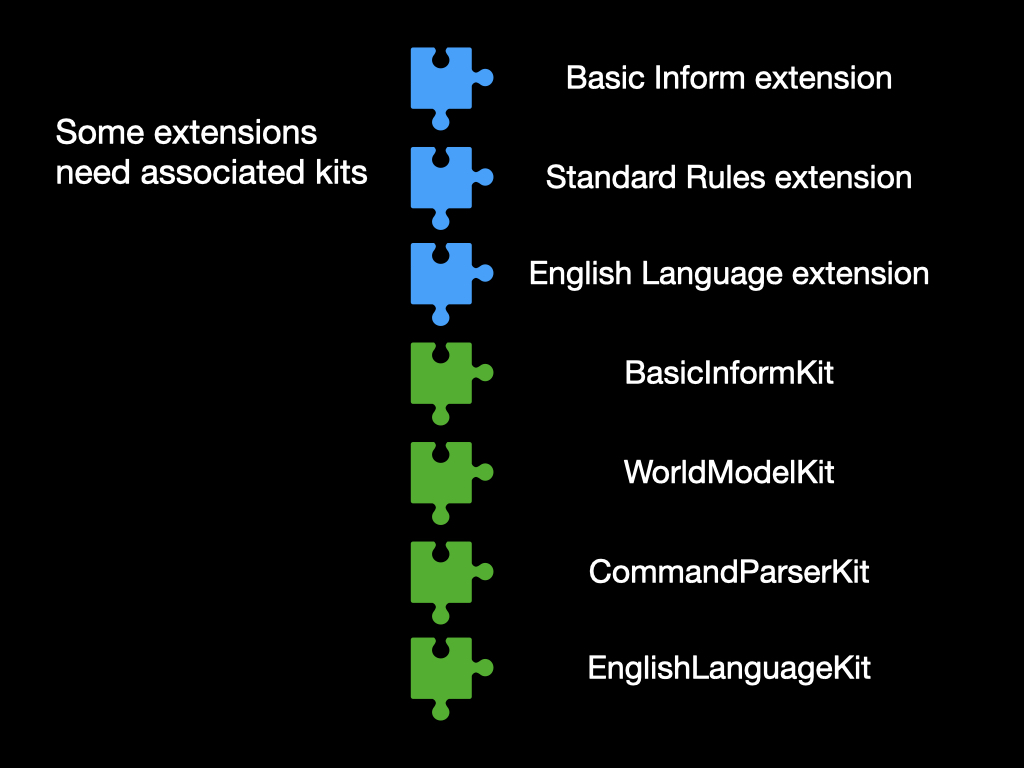
And even so, there’s no way for an extension to come with associated images, data files, sound effects, or kits, for example. Similarly, a French Language extension can’t come with Preform files of language syntax or with natural language metadata somehow built in. All of this makes it a nuisance to distribute really ambitious features with extensions. Three of the extensions supplied in the core Inform distribution need kits to make them work, I note.
IE-0001 therefore presents a comprehensive expansion of the extension format. Existing one-file extensions will work exactly as they do now, but it will be easy to migrate those to “directory format”.

Once that has been done, a whole host of optional extras can be added:
Red Fire Hydrants-v1_3
extension_metadata.json
Source
Red Fire Hydrants-v1_3.i7x
Documentation
Documentation.txt
Examples
Alpha.txt
Zulu.txt
Images
diagram.jpg
Materials
Inter
RedFireHydrantsKit
DefaultFireFightersKit
Figures
dalmatian.jpg
Sounds
gushing.mp3
Particularly notable here is that directory-format extensions can provide JSON-format metadata, allowing them, for example, to say that certain features in the Inform compiler should be turned on or off when the extension is used.
This set of changes is major enough that the Inform apps will need changes to accommodate it, especially in how they download extensions and install them.
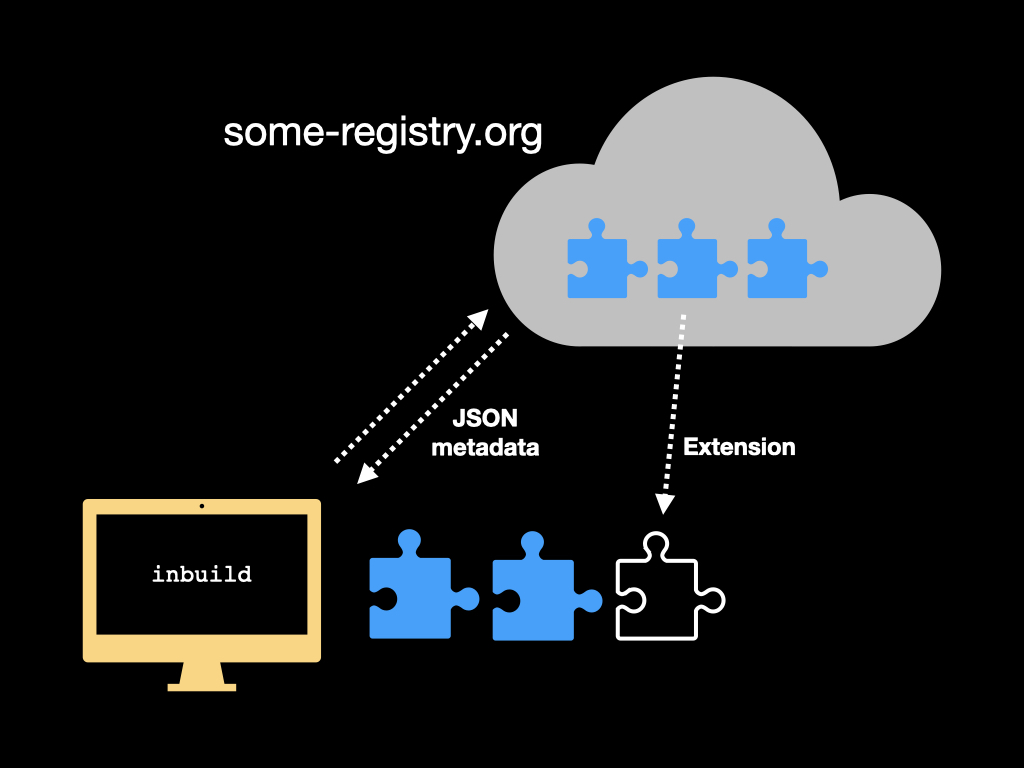
To digress for a moment, IE-0001 is really part of a wider manifesto for how Inform resources are distributed. At present, only extensions are really shared among Inform users, with a sort of central registry, the Public Library, which doesn’t do a very good job at present. But it doesn’t handle versioning well, it’s selective, and people may want registries of their own.
Inform’s build manager, inbuild, should some day solve all this. It sorts out metadata and works out dependencies between Inform resources: it can say exactly what extensions and kits are needed to compile an Inform project, for example, and which versions would be needed. Work has already begun on giving inbuild a formal concept of “registry”, an Internet location - almost certainly a Github repository - holding Inform resources which inbuild could, in principle, browse and fetch from. But inbuild cannot yet fetch missing resources from the Internet.
While we will want to generalise this so that anyone can set up a registry, we probably also want a central registry - compare RubyGems for Ruby, the Node Package Manager npm registry, or the Comprehensive Perl Archive Network. The “Friends of I7” collection of extensions is already something like this, but not quite. This is all too hazy to have a numbered proposal yet, but we can see it shimmering in the distance.

That takes us to the huge proposal IE-0009, which we’re calling “Dialogue”. This may completely change how Inform is used in practice, and opens up the possibility of creating entirely different interactive experiences. The one-sentence pitch for this feature would be: Flowing conversation as easy to write as in IF languages like Ink or Twine, but the full power of Inform’s world model and natural language conditions and actions underneath always available to enhance that.
IE-0009 is intended to help authors of command-parser IF incorporate dialogue better into projects, and it is intended to help authors of non-command-parser IF to write entirely dialogue-based stories, and it is intended to help users in the commercial space to build dialogue engines into games which may not be graphical at all.
We see no contradiction in serving all three of these groups of users. We’re a big, varied, and exciting community, doing all kinds of things in all kinds of ways. Authors of the 2020s want different things than the authors of the early 2000s, and Inform exists to serve authors, not the other way around.

While IE-0009 makes enormous additions to Inform, it takes away almost nothing, so it will be a non-disruptive change for existing users. But because the change is so huge, it’s likely to be introduced in a major, not minor, release of Inform, perhaps as the lead feature of Inform 11.1.
Well, so what is Dialogue? It’s the ability to have sections of an Inform source text which look like a printed play or movie script rather than like a printed novel or short story. Dialogue was designed by Emily Short, who is one of the world’s leading narrative designers, and in particular is an expert in this conversational-modelling space. It looks simple and easy to write, but gains great flexibility from being underpinned by the full power of Inform underneath.

Section headings are nothing new in Inform, of course, but here one has been marked as containing dialogue. That means the sentences under this heading follow a quite different syntax.

Assertions, rules and tables are all forbidden, and instead we have “dialogue beats”. A satisfying scene in a story is probably going to be many beats, flowing one into another. A “beat” can be multiple lines of dialogue or narration, but with a single reason for being performed - that’s called the cue, and is written in brackets.
Note that beats can be “about” people, things or abstract ideas - indeed, we have another proposal, IE-0010, for a new kind called “concept” to be used by Inform for abstractions. So you could create a concept called “world peace”, say, and then use that as a conversational subject. But here we have a fence, which is a thing in the story.
The lines of dialogue are only performed if the people saying them are audible to the player. If the potential speaker is somewhere else, or has left the story somehow, the line won’t be spoken.
You can also add all sorts of standard Inform world model, and have dialogue depend on it. Building this out:

Note that Huck now speaks only if the fence is unpainted.
All this may look like a simple dialogue tree, but it’s much more flexible than simple examples show. This, for example:
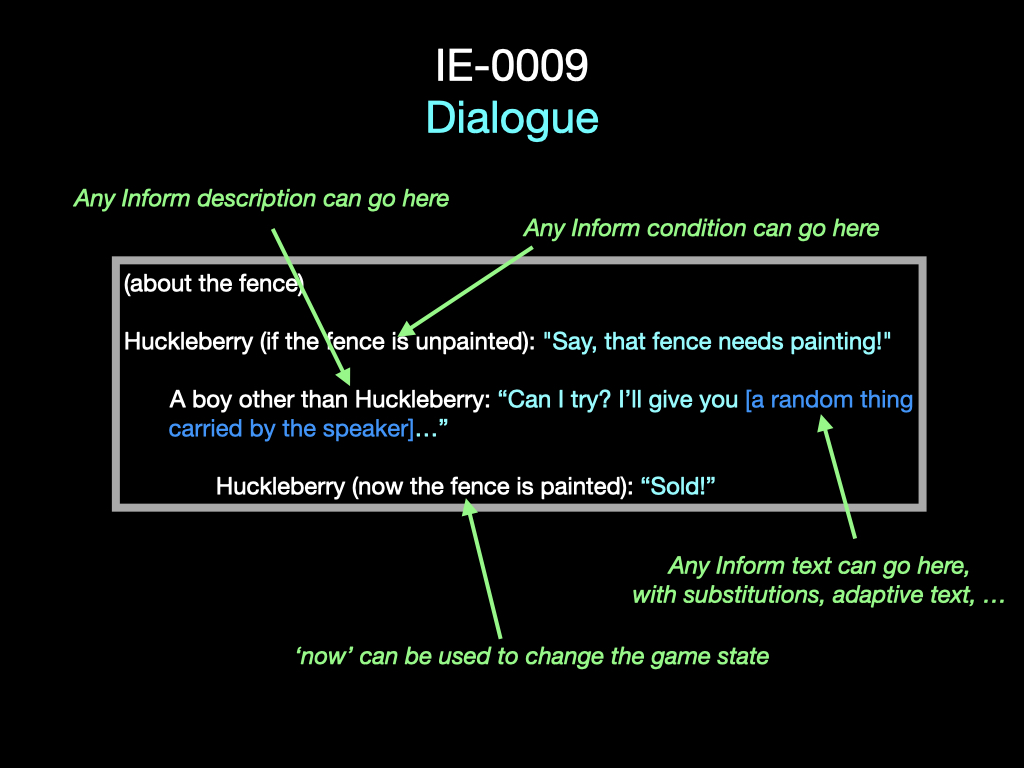
One of the lines here is performed by “A boy other than Huckleberry”. At runtime, a speaker will be selected who is audible, a boy, and not Huckleberry. (That person might be the player.) And in general, almost everything you see in these slides can be customised with the full flexibility of Inform.

Dialogue can also be conditional on someone being available to talk to.
Huckleberry (to Tom): "I'm getting an idea."
This also makes Tom the most likely person to reply, if there’s a choice.

Conversation does not always flow on rails laid out by the author, and can also naturally pick up conversational subjects. The author could write:
Huckleberry (mentioning the fence): "See that wind-blown old fence?"
That line might end the beat, and yet not end the conversation, because it might lead to another beat:

(about the fence)
Tom: "My father hammered that ol' fence in back when we put up the barn."
A runtime system called the “director” chose that beat to be performed next because it knew that the subject of the fence was hanging in the air after Huckleberry’s previous line.

Dialogue can not only depend on the state of the world but also change it:
Huckleberry (if the fence is unpainted): "Say, that fence needs painting!"
Tom (now the fence is painted): "Let me have that brush... All done."
And there are actions, too, which as always in Inform can be performed by any character:
Huckleberry (after taking the paintbrush): "I'm going to fix this."
If the action Huckleberry taking the paintbrush fails for some reason, the line of dialogue is not performed. And so on.

Next we come to choices. In the dialogue system, we’re offering choices in two different ways: one where there’s an explicit set of choices for the player to choose from, and one where it’s open-ended and left up to parser commands. Here’s a simple choice of just two options.
Huckleberry: "Should we go to the schoolhouse now?"
-- "No, I'd sooner build a raft!"
Huckleberry: "Guess we do live near the Mississippi..."
-- "I s'pose."
Narration: "Huck's face falls."
There’s a whole automatic process of not reoffering options, of making options conditional on the world state, and so on: it’s much more flexible than this example shows. Indeed, the “director”, the runtime manager for conversation, does its work through activities and rulebooks, just like other components of Inform, which makes it highly customisable.

All of this makes it possible to create sophisticated choice-based fictions with the same sort of ease as the original Inform made command-parser fictions. But you can have a command parser as well, or instead, or mix the two exactly as you would like. Here are choices presented via the command parser:
Huckleberry: "What'll we do about this fence?"
-- instead of examining the paint
Huckleberry: "That pot came on the railroad right from Ohio."
--
Huckleberry: "Guess we'll leave it for now."
Here, the dialogue breaks off for a turn of the story. In a command-parser game, that means giving the player the opportunity to type a command, parsing it, turning that into an action, and trying the action. What happens here is that if the player asks to examine the paint, Huckleberry cuts in and the dialogue continues.
Choices are also highly customisable and there’s much more that we could say, but the full proposal is at inform-evolution, and that finishes this tour of new features on the near horizon.

There are also hazier hopes for the future of the programming language, which haven’t reached any kind of proposal as yet. As mentioned, one is better support for the fetching and publishing of shared resources like extensions. Another is support for additional data structures, and better ways to handle namespace collisions.

The Inform tool-chain is no longer tied to interactive-fiction specific virtual machines - it can now turn interactive fiction into native C programs. You might ask, how does that help anyone? Well, they do run faster as native code, as it happens, but the real point is that they can be linked into larger, external projects much more easily.
In particular, a large commercial game build on technologies like Unity or Unreal Engine could now, in principle at least, use an Inform source text as its dialogue engine, or just to generate dynamic text needed at some point in its gameplay. We want Inform to do what it can to serve those users. There is precedent for this: Ink has plugins for both Unity and Unreal Engine.
How much progress we can make on that will depend on whether volunteers come forward who are able to build out the Unity/Unreal side of the technology needed. But here is the picture as I see it:
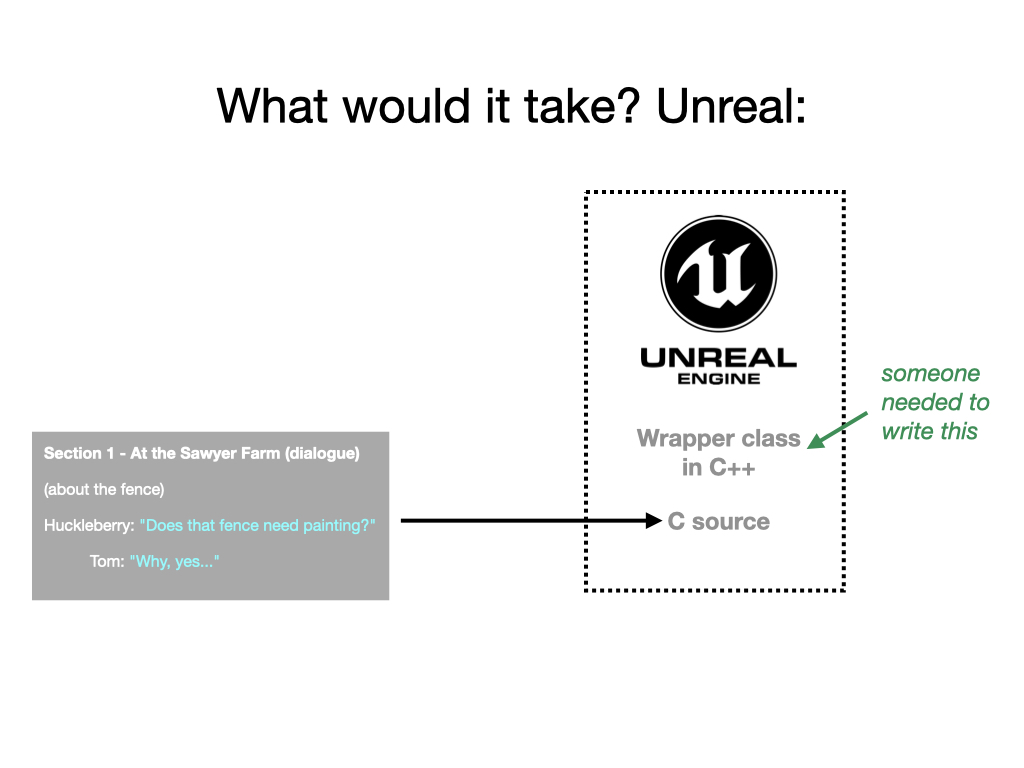
Unreal Engine may be the easier target, though with some limitations. Unreal is a game engine with a built-in scripting language called Blueprint. It’s possible to write games using only Blueprint scripts, so that you never compile at all - you’re just using Unreal as an interpreter. It’s hard to see how those developers could access material produced by Inform. But games on Unreal more usually do recompile the engine themselves, sometimes to extend its features, or wrap them up in some way. Since the engine is written in C++, it is relatively easy to link it with code written in C, like the output of Inform. But in order to make this a good experience for developers using Unreal, we would need somebody to write a C++ wrapper which would nicely wire up functions provided by Inform to scripting features in Blueprint.
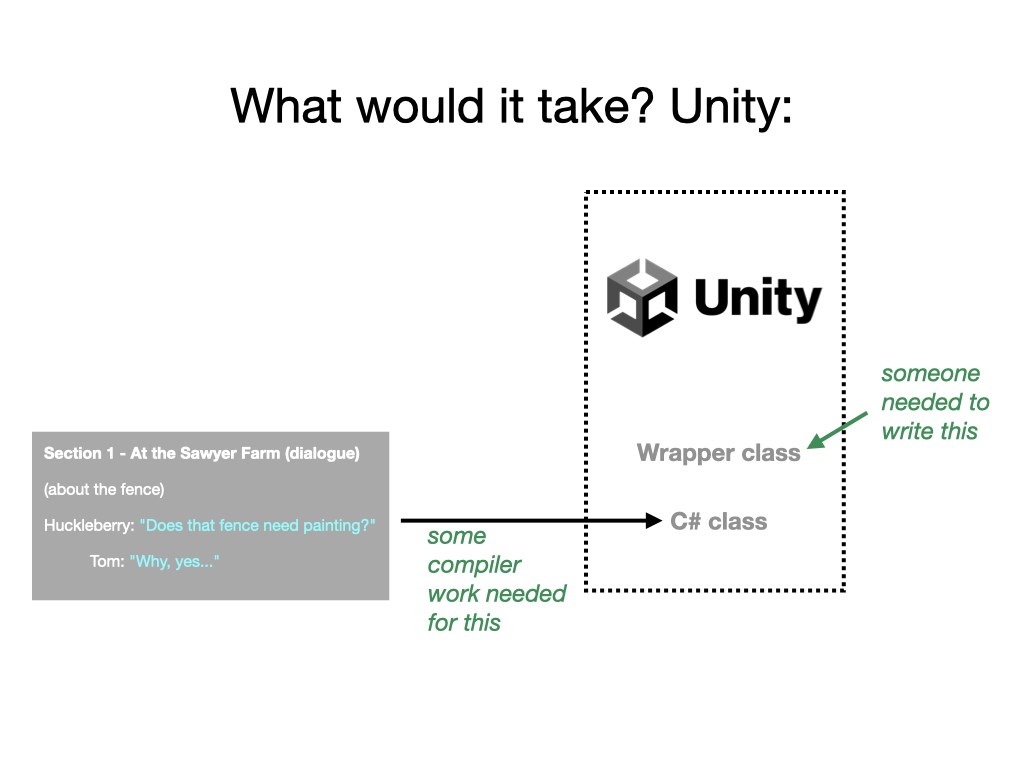
The picture on Unity is similar, but with a complication, which is that the Unity engine is written in C#, not C++, and C# is slightly troublesome at interfacing with C code. It’s certainly possible to get around this, but we think a cleaner plan would be to add C# as a new output language from Inform. An Inform source text might then compile to a single C# class, which, again, might need some wrapper code to be conveniently accessible to Unity developers.
As I say, whether we can make progress will depend on whether people, either in the commercial space or hobbyists using these tools, are interested in giving this a try. But the API from the Inform side is already built and working, and the advice we’ve had is that the task of making plugins for these engines shouldn’t be too difficult from here.

Providing text-handling for game engines is only one way which Inform could be a component of some hybrid system. I’m going to be very brief here, but a handful of examples might suggest how many possibilities exist.
First, commercial-space games could still use Inform, even if text plays very little part in them. Inform actions could provide logic for modelling what the player can do with interactive objects in the game. Rules and rulebooks can be used to model NPCs and what they do in response to movement, or other stimuli. Inform scenes can be used as part of a storylet selection system, choosing which game scenes play out next.

More abstractly, Inform can be used to generate text. Pseudo-random text is as old as gaming — the 1984 BBC Micro game “Elite” featured pseudo-random galaxy maps with planets exporting “carnivorous arts graduates” — but the suggestive qualities of proc-gen text are now made for their own sake. Emily Short’s “Annals of Parigues” is a good example, and was partly written using Inform.
But this could be taken further. Proc-gen text made by Inform could be used to create training data for larger text systems, for example. Or we could imagine using Inform to create a toy world in which other AI-driven generators could be tested and trained.

Lastly in this brief section, consider the possibilities of creating Inform content — either dynamically or in advance — using GPT-3, a so-called Large Language Model. Here are a handful of little playground experiments running in OpenAI.
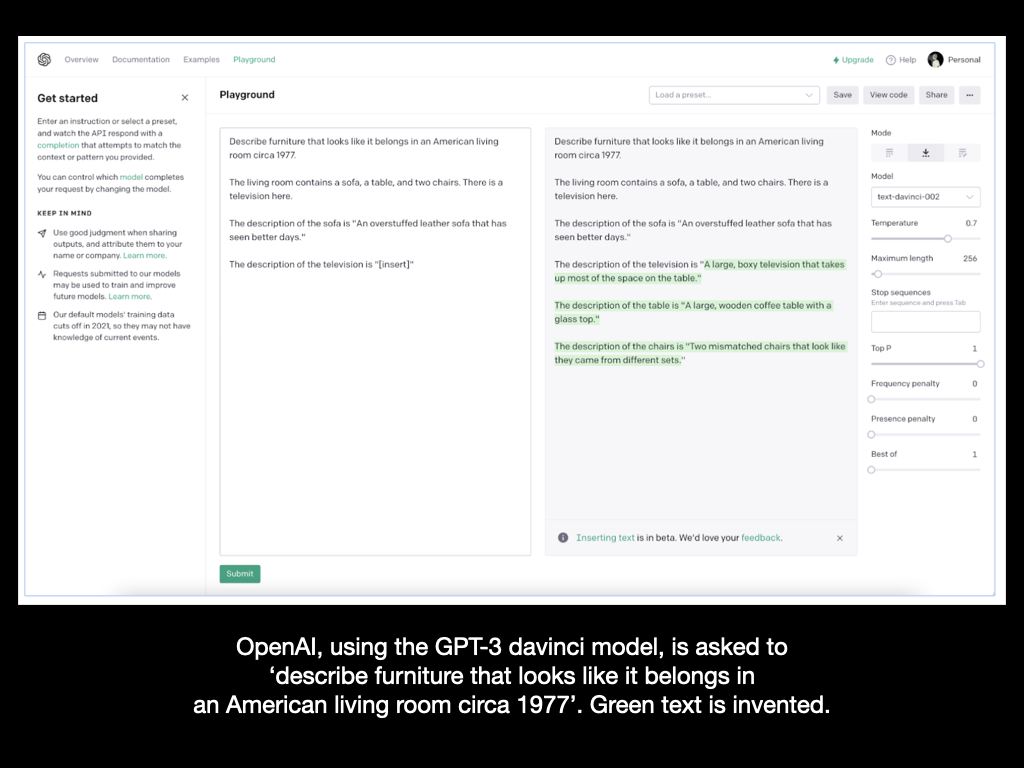
The davinci model is asked here to ‘describe furniture that looks like it belongs in an American living room circa 1977’. Green text is invented. It has chosen to call the TV set “A large boxy television that takes up most of the space on the table.”
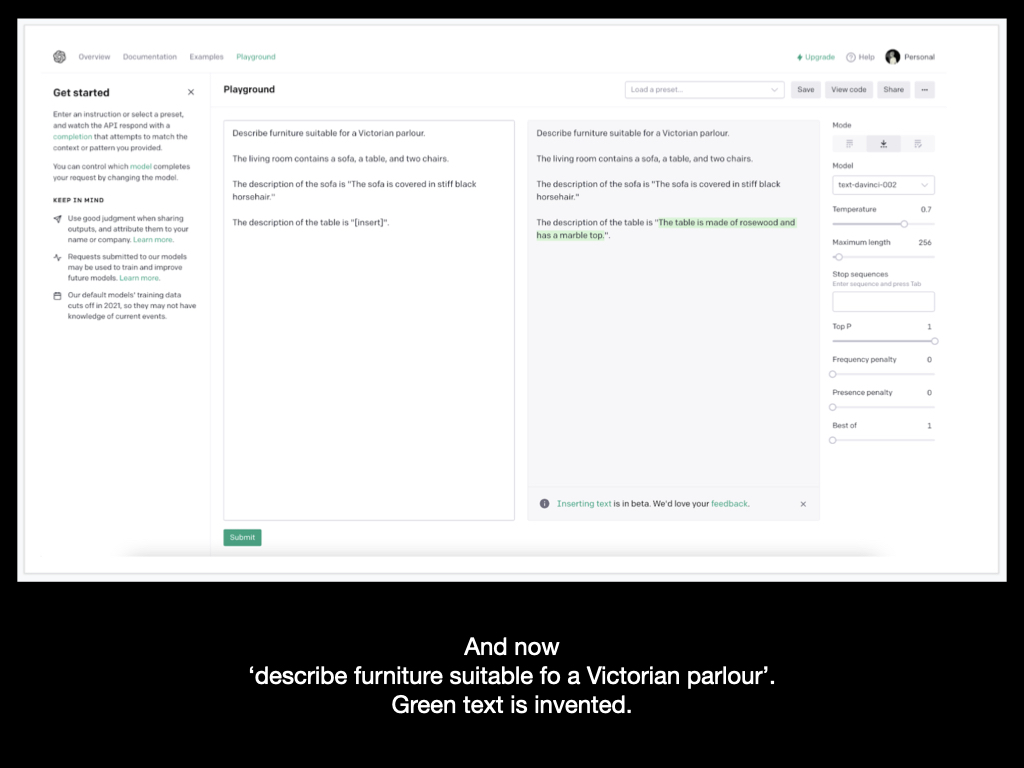
Told instead that the situation is Victorian, it says the table is “made of rosewood and has a marble top”.
There are all sorts of obstacles to using GPT-3 in production games. It’s commercial, and the fees scale badly. And like all large language models, it tends to hallucinate, and may say things you really don’t want it to say. All the same, this technology is on the march. My point with these slides was just to say: in its new architecture, Inform could be connected to a lot of other stuff.